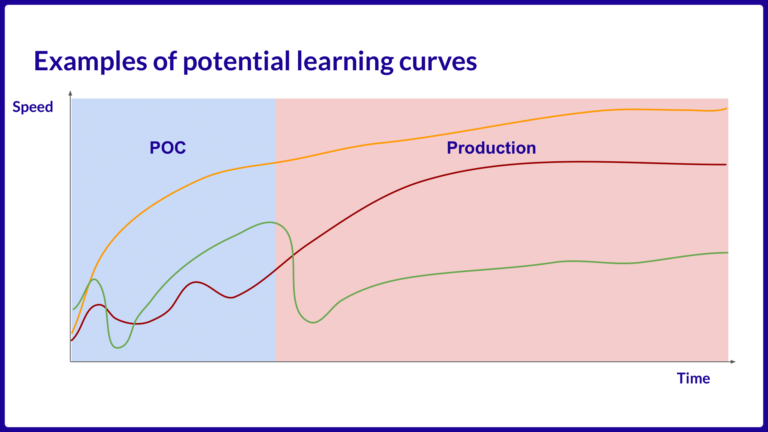
Introduction
Dans les échanges initiaux avec nos clients, la question de la précision d’annotation est systématiquement au centre des discussions. Qu’il s’agisse de boîtes englobantes (bounding boxes) ou de masques de segmentation, l’exigence est souvent la même : obtenir des annotations les plus précises possibles, un alignement au pixel près.
Cette demande est légitime, car l’intuition nous dicte que plus l’annotation est précise, meilleure sera la performance finale du modèle.
Cependant, cette quête de la perfection géométrique soulève une question critique pour les ingénieurs et les chefs de projet : cet investissement humain supplémentaire se traduit-il réellement par un gain équivalent dans les métriques algorithmiques (mAP, IoU) de votre modèle ?
Nous allons analyser, à partir des résultats de plusieurs études récentes, comment différents types d’imperfections d’annotation affectent réellement la performance des modèles, et où se situe le point d’équilibre entre effort d’annotation, coût et gain algorithmique.
Définition des métriques clés
IoU (Intersection over Union) : Cette métrique mesure la précision de la localisation d’un objet. Elle mesure le taux de chevauchement entre la prédiction du modèle et la vérité terrain (ground truth).

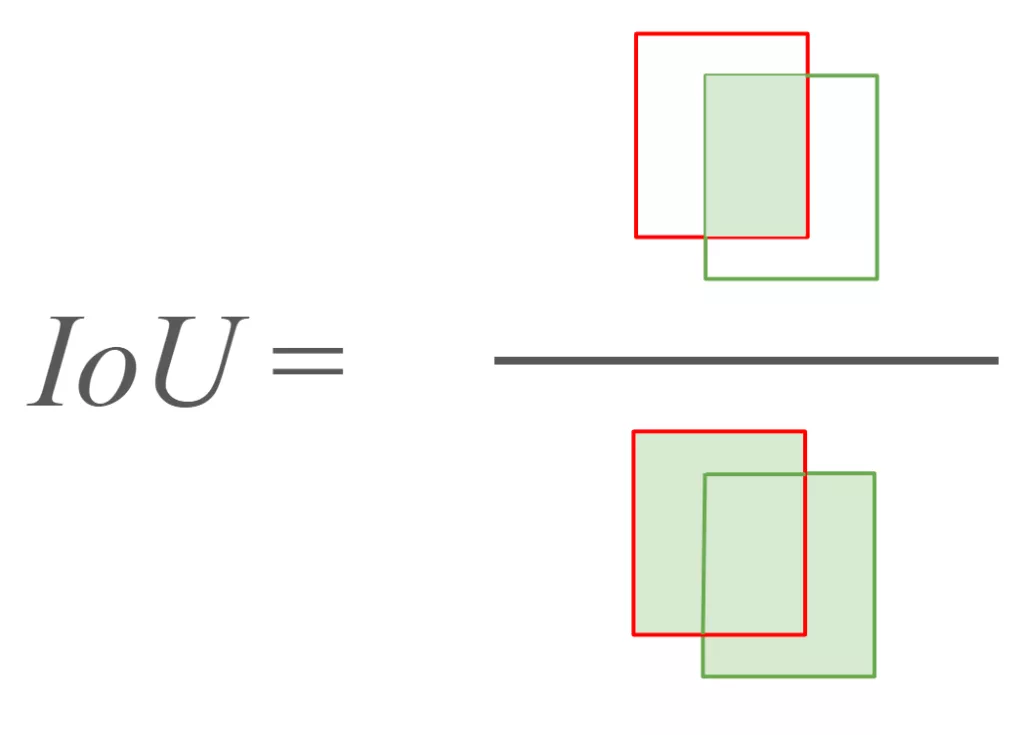
mAP (Mean Average Precision) : Cette métrique mesure la qualité globale d’un modèle de détection d’objets.
- Elle combine à la fois la précision (combien de détections sont correctes) et le rappel (combien d’objets ont été détectés parmi tous les objets présents).
- On calcule d’abord la précision moyenne pour chaque classe d’objets (AP), puis on fait la moyenne sur toutes les classes pour obtenir le mAP.
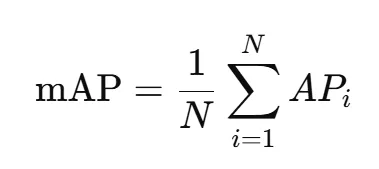
1. Le phénomène des rendements décroissants : Bbox et bruit géométrique
L’investissement humain dans la précision géométrique est régi par la règle : le coût croît de manière exponentielle lorsque l’on s’approche de la perfection (correction d’erreurs infimes, plusieurs cycles de revues). Pourtant, la performance des modèles ne suit pas cette courbe.
Etude Universal Noise Annotation
L’étude Universal Noise Annotation a cherché à quantifier l’impact réel des imperfections d’annotation par des bounding boxes (Bbox). Pour ce faire, les chercheurs ont mis en place une méthodologie rigoureuse :
- Datasets et modèles testés : L’analyse a été menée sur des jeux de données de référence (comme COCO), en testant la résilience de plusieurs architectures de pointe en détection d’objets (incluant souvent des modèles basés sur les R-CNN ou les Transformers).
- Injection de bruit systématique : Au lieu d’utiliser des annotations humaines « naturellement » bruyantes, l’étude a simulé et injecté des erreurs d’annotation de manière contrôlée, en faisant varier le taux et le type de bruit (5%, 10%, 20% des annotations sont corrompues) et en mesurant la chute de la mAP correspondante.
L’étude a distingué trois grandes catégories de bruit, avec des impacts très différents sur la performance algorithmique :
- Bruit de classification (Categorization) : Attribution d’une mauvaise étiquette de classe (ex: annoter une « voiture » au lieu d’un « camion »).
- Bruit géométrique (Localization) : Il s’agit du décalage, du redimensionnement ou du contour imparfait des Bbox.
- Bruit de présence (Missing ou Bogus) : Oublier d’annoter un objet visible (faux négatif) ou annoter un objet inexistant (faux positif).

Le résultat clé : la tolérance à la géométrie
Le constat est clair : les modèles testés sont tolérants aux imprécisions modérées du bruit géométrique.
Même avec une quantité significative d’erreurs de localisation simulées, les algorithmes ont montré une chute de performance minimale en mAP car ils continuent d’apprendre les caractéristiques contextuelles et la signature visuelle de l’objet.
L’investissement pour éliminer les dernières marges d’erreur géométrique est soumis à la loi des rendements décroissants. L’effort supplémentaire exigé pour passer d’une IoU moyenne de 0,85 à 0,90 est démesuré par rapport au gain final en capacité de détection.
Par ailleurs, l’étude a montré que les modèles sont beaucoup plus sensibles au bruit de classification et surtout au bruit de présence. Oublier d’annoter un objet (ou lui donner une mauvaise étiquette) a un effet beaucoup plus destructeur sur la mAP que de mal cerner légèrement son contour.
Et lorsque les trois types de bruit (classification, géométrie, présence) sont combinés au-delà d’un certain seuil, la performance s’effondre brutalement.
Ceci renforce notre argument : l’effort d’annotation doit se concentrer sur l’exactitude sémantique et l’exhaustivité (ne rien manquer), et non sur la perfection géométrique.
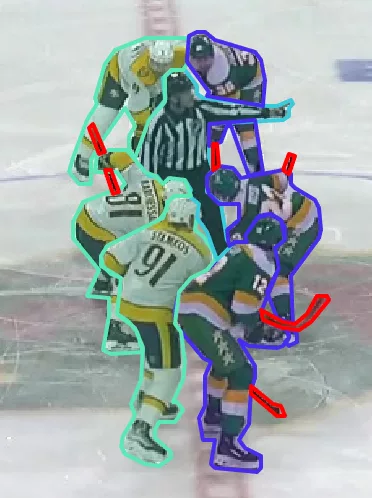
Sur cet exemple de Bbox de joueurs de hockey sur glace pour notre client Stathletes, entre une Bbox “parfaite” et une Bbox plus approximative : le temps d’annotation peut être doublé voire triplé.

2. Bbox vs. Segmentation : la justification du coût géométrique
Si l’imprécision modérée de la Bbox est tolérée par le modèle, qu’en est-il de la segmentation d’instance ? Le choix de la segmentation est synonyme de précision accrue, mais il s’accompagne d’un coût d’annotation intrinsèquement plus élevé. La question devient : cette précision est-elle justifiée par la tâche, ou est-ce une dépense inutile ?
L’écart coût-temps
La différence de coût entre la Bbox et la segmentation (polygones) est significative :
Coût de l’annotation : sur la base de notre expérience, selon la qualité de l’image et la complexité de l’objet à annoter, l’annotation d’une bbox peut prendre de 3 à 10 secondes alors que l’annotation d’un masque peut prendre de 20 secondes à plusieurs minutes.
Conséquence : Payer significativement plus cher pour la segmentation doit se justifier par un impératif technique où les contours précis, la forme ou les mesures de surface sont critiques (ex: imagerie médicale, calcul de chemin ou de trajectoires pour les systèmes autonomes, ou encore inspection de défauts).
Pour les cas d’usage axés sur la localisation et le comptage (où une IoU de 0,7 est suffisante), l’investissement dans la segmentation est une erreur d’optimisation des ressources. Il vaut mieux utiliser ces ressources pour augmenter la quantité et la diversité du jeu de données (levier de performance bien plus puissant).
Dans le cadre de nos travaux d’annotation pour notre client Stathletes, nous avons enrichi l’annotation basée sur des bounding boxes pour la détection des joueurs par une annotation de segmentation (masques). Cette approche permet une meilleure séparation des instances dans des scènes à forte densité, notamment lors de regroupements de joueurs ou de chevauchements partiels, où les bounding boxes seules atteignent leurs limites en termes de précision de détection.
Autre exemple d’annotation par segmentation : utilisation de masques pour détecter les différentes zones de la surface de jeu (repérage de localisation précise).

Remarque : des recherches récentes montrent que des modèles spécifiquement conçus pour gérer le bruit, comme ceux basés sur des Vision Transformers et des stratégies d’apprentissage adaptatif (ADL), peuvent compenser activement les annotations bruitées, permettant d’obtenir des résultats fiables même lorsque les données d’entraînement ne sont pas parfaites. Voir par exemple cette étude : Dealing with Unreliable Annotations: A Noise-Robust Network for Semantic Segmentation through A Transformer-Improved Encoder and Convolution Decoder.
3. L’intervention technologique : SAM et la fin de l’annotation humaine coûteuse
L’arrivée des modèles de foundation en vision par ordinateur, comme le Segment Anything Model (SAM) de Meta AI, transforme l’annotation par segmentation. En étant entraîné sur le jeu de données massif SA-1B (plus d’un milliard de masques), SAM est capable de généraliser et de produire des segmentations précises, y compris sur des objets jamais vus auparavant (zero-shot learning).
Efficacité et précision accrues : L’intégration de SAM dans les outils d’annotation permet de générer des masques de haute qualité à partir d’une simple Bbox ou d’un point. Cela accélère considérablement le processus d’annotation, réduit les erreurs et incohérences humaines, et diminue ainsi le coût global tout en améliorant la productivité.
Pour les projets exigeant une haute précision, l’annotation assistée par modèle (Model-in-the-Loop) devient la méthode la plus efficace : l’effort humain se concentre sur la validation et l’ajustement rapide des masques générés par l’IA, plutôt que sur la création manuelle exhaustive.
L’introduction de SAM (Segment Anything Model) rebat donc en partie les cartes en réduisant significativement le coût d’accès à des annotations de haute qualité.
En automatisant ou en assistant efficacement les tâches de segmentation fine, SAM permet d’envisager un investissement accru dans la qualité des annotations sans augmentation proportionnelle des coûts ou des délais. Cette évolution rend ainsi plus accessible l’utilisation de jeux de données à forte valeur ajoutée, jusque-là réservés à des projets disposant de budgets importants.
Exemples d’annotation d’un joueur de hockey en utilisant la Bbox SAM puis corrections marginales effectuées par l’annotateur.


Remarque : pour des objets plus petits et/ou plus flous, SAM n’est pas toujours la solution la plus rapide.
⚠️ Confidentialité des données : L’usage de modèles externes comme SAM peut être limité pour des données sensibles (ex : données personnelles, médicales ou secrets industriels). Ces outils nécessitent souvent de transférer les données sur la plateforme du fournisseur de l’outil d’annotation. Dans ces cas, les contraintes réglementaires (RGPD, propriété des données) peuvent imposer de recourir à une annotation manuelle, même si le coût est plus élevé.
À lire aussi : SAM en annotation de données : quand et comment l’utiliser.
4. Stratégie de données : calibrer l’annotation pour un impact optimal
La meilleure approche consiste à adapter l’effort d’annotation aux besoins réels de la tâche, en tirant parti de la robustesse des modèles et des outils avancés comme le Segment Anything Model (SAM) pour la segmentation.
- Établir le seuil fonctionnel : Définissez l’IoU ou la précision de segmentation minimale nécessaire pour que votre application atteigne ses objectifs. Si une IoU de 0,7 ou un masque légèrement approximatif suffit, chercher à atteindre une perfection géométrique (IoU > 0,85) représente un investissement à rendement décroissant.
- Optimiser la quantité et la diversité : Les ressources économisées en renonçant à la sur-précision peuvent être réinvesties dans l’augmentation du nombre et de la variété des données annotées. Pour la majorité des modèles, plus de données diversifiées avec une précision « très bonne » surpassent peu de données annotées de manière parfaite.
- Exploiter l’annotation assistée par modèle : L’intégration de modèles comme SAM permet de générer rapidement des masques de haute qualité à partir de simples points ou bounding boxes. L’effort humain se déplace alors de l’annotation complète à la validation et au raffinement, réduisant le coût et le temps nécessaires tout en maintenant une cohérence élevée.
En définitive, l’expertise en annotation ne consiste plus à viser la perfection géométrique, mais à concevoir une stratégie de données intelligente : calibrer la précision, maximiser la diversité et tirer parti des outils d’IA pour obtenir un gain algorithmique optimal à coût maîtrisé.
Vous souhaitez aligner la précision de vos annotations sur les besoins réels de vos modèles IA ? Contactez nous pour discuter de votre stratégie.