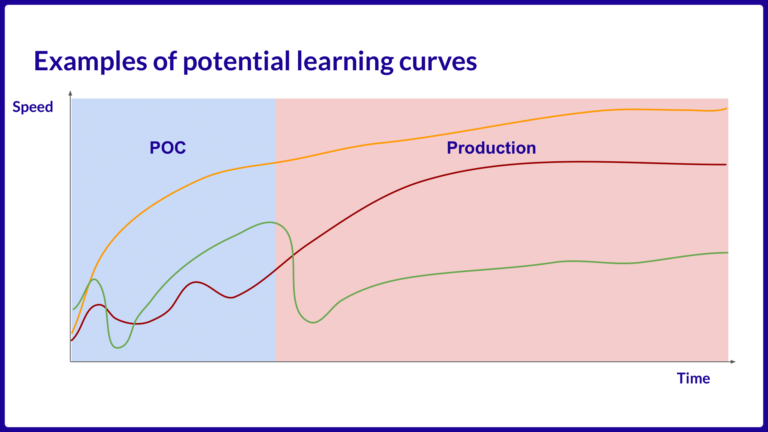
L’objectif de cet article est de clarifier le contexte et le fonctionnement de l’annotation de données, ainsi que ses principales caractéristiques. Notre article est divisé en quatre sections:
- De l’IA jusqu’à l’Annotation de Données : Quelques concepts clés.
- Importance d’avoir de bonnes données : “Data-centric AI”.
- Annotation de données
- Peut-on échapper à l’annotation de données?
De l’IA jusqu’à l’Annotation de Données : Quelques concepts clés
Avant de plonger dans les spécificités de l’annotation de données, essayons de comprendre dans quel contexte elle intervient.
Nous évoluons dans le domaine de l’Intelligence Artificielle (IA). Le Larousse définit l’IA comme : « Ensemble de théories et de techniques mises en œuvre en vue de réaliser des machines capables de simuler l’intelligence humaine. » et définit l’intelligence comme étant aussi « la capacité de s’adapter à de nouvelles situations. »
Plus précisément, l’Encyclopædia Britannica définit l’Apprentissage Automatique (ou Machine Learning en anglais) comme « la méthode pour entraîner un ordinateur à apprendre de ses entrées (inputs), mais sans programmation explicite pour chaque situation. »
Ces méthodes, ou algorithmes, pour entraîner un ordinateur à apprendre (Machine Learning) peuvent être soit supervisées, soit non supervisées.
L’apprentissage supervisé et non supervisé
L’apprentissage non supervisé implique des algorithmes analysant des données non annotées pour tenter d’identifier des schémas, structures ou relations inhérentes parmi les points de données. Contrairement à l’apprentissage supervisé, l’algorithme apprend à partir de données non annotées. Ces données non annotées n’ont pas de sorties (outputs) prédéfinies. Au lieu de cela, l’algorithme cherche à trouver des similitudes ou des groupements au sein des données de sa propre initiative, comme regrouper des points de données similaires en fonction de leurs caractéristiques. Imaginez un explorateur s’aventurant en territoire inconnu sans carte.
Supervised learning algorithms learn by using labeled examples where input data is paired with corresponding desired outputs. This enables the algorithm to understand patterns and relationships between inputs and outputs, which it can then apply to new, unseen data. Imagine a teacher guiding a student with problems and their solutions.
Les algorithmes d’apprentissage supervisé ont de nombreuses applications dans la vie réelle. Par exemple, la détection de visages, la catégorisation de textes, les prédictions boursières, la détection de spams, etc. Nous nous pencherons sur certains d’entre eux plus tard.
Lorsque nous travaillons avec des algorithmes d’apprentissage supervisé, nous avons besoin des « réponses aux problèmes » – c’est-à-dire que nous avons besoin que les données aient une annotation adéquate qui les catégorise correctement. Cependant, les données non structurées ne viennent pas naturellement avec des “réponses” (par exemple, images, vidéos, phrases, c’est-à-dire lorsque nous prenons une photo, la photo ne dit pas si la photo comporte un chien ou un chat, et le cas échéant, où il se trouve). Pour avoir ces informations, nous avons besoin d’annotation de données.
L’annotation de données est le processus d’ajout d’annotations significatives et informatives aux données brutes (par exemple, images, fichiers texte, vidéos, etc.) pour fournir un contexte afin qu’un modèle d’apprentissage automatique puisse apprendre. L’annotation de données est nécessaire pour une variété de cas d’utilisation, y compris la vision par ordinateur (computer vision), le traitement du langage naturel et la reconnaissance vocale.
L’importance d’avoir de bonnes données
Pour citer Kili Technology, l’un de nos partenaires : « Allons droit au but : l’efficacité des modèles d’apprentissage automatique repose uniquement sur la qualité des données utilisées pour leur apprentissage. » Nous sommes persuadés que pour réussir avec l’Intelligence Artificielle, une entreprise a besoin de données annotées de haute qualité pour former son modèle.
Nous savons que l’utilisation de données mal annotées ou de faible qualité lors de l’apprentissage d’un modèle est préjudiciable. Mais quelles sont les estimations de cet impact ?
- Une étude de 2016 d’IBM a révélé que la mauvaise qualité des données coûte 3,1 billions de dollars à l’économie américaine chaque année en raison d’une baisse de la productivité, de pannes de systèmes et de coûts de maintenance élevés, pour ne citer que quelques-unes des conséquences négatives possibles.
- Le cabinet de recherche IDC a estimé la taille du seul marché des big data à 136 milliards de dollars par an à l’échelle mondiale, en 2016.
Data-centric AI (L’approche de l’IA axée sur les données)
Cette idée selon laquelle des données de mauvaise qualité nuit à nos entreprises s’est renforcée ces dernières années. Elle est notamment due à la prise de parole d’experts comme Andrew Ng qui préconisent des approches d’IA axées sur les données et qui sensibilisent ses confrères. Andrew Ng définit le Data-Centric AI (c-à-d l’IA axée sur les données) comme « la discipline consistant à systématiquement imaginer en amont les données nécessaires pour bâtir avec succès un système IA. » Les systèmes d’IA ont besoin à la fois de code et de données, et Andrew Ng a déclaré lors d’une conférence EmTech Digital 2022 organisée par MIT Technology Review, que « tous ces progrès dans l’algorithmie nous indiquent qu’il est temps de consacrer plus d’énergie aux données. »
Ce courant de pensée estime que le model-centric AI (c-à-d l’IA centrée sur le modèle) a pour objectif de « produire le meilleur modèle pour un ensemble de données fini », tandis que le Data-Centric AI a pour objectif de « produire systématiquement et algorithmiquement le meilleur ensemble de données pour alimenter un modèle Machine Learning donné ».
« Mon point de vue est que si la préparation des données représente 80% de notre travail, alors le travail le plus important d’une équipe d’ingénieurs en Machine Learning est de s’assurer de la qualité des données en entrée. »
Andrew Ng, qui a participé à l’essor de modèles d’apprentissage profond massifs formés sur le big data, mais qui prêche maintenant des solutions basées sur de plus petites quantités de données.
Lorsque nous considérons la rentabilité d’une approche centrée sur les données, il est clair que l’investissement initial dans une annotation de données de qualité peut entraîner des avantages à long terme substantiels, car la précision et la qualité des données influencent directement sur l’efficacité d’un système d’IA. Cette synergie entre le Data-Centric AI et l’annotation de données provient du fait qu’une base de données d’entraînement de qualité est fondamentale pour tout succès dans l’IA.
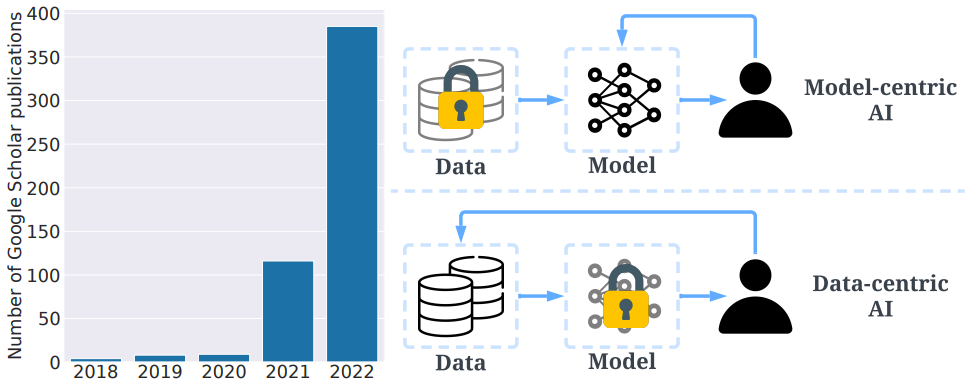
Nous savons maintenant que nous pouvons avoir besoin d’annotation de données pour travailler avec des algorithmes d’apprentissage supervisé, et que les algorithmes d’apprentissage supervisé sont un type d’algorithme de Machine Learning (apprentissage automatique). Nous avons également compris la nécessité de se concentrer sur des données de haute qualité.
Commençons donc à explorer l’annotation de données.
L’annotation de données
L’annotation de données est un domaine vaste qui englobe de nombreux cas d’usages et types de données au sein de diverses industries. Pour bien comprendre ce qu’est l’annotation de données, clarifions d’abord certains éléments :
- Quels sont les types de données que nous pouvons annoter ?
- Quelles sont les types d’annotations que nous pouvons ajouter aux données ?
- Quelles approches pour annoter une donnée ?
- Quels outils de pré-annotation et outils automatiques/semi-automatiques ?
Types de données
Les types de données font référence au format et à la nature des données annotées. Dans le contexte de l’annotation de données, les données peuvent être catégorisées en différents types, tels que :
- Données textuelles : Comprend les documents textes, les documents PDF, les publications sur les réseaux sociaux, les e-mails, les articles, etc.
- Données d’images : Comprend le contenu visuel sous forme d’images ou de frames extraites de vidéos.
- Données audio : Comprend les enregistrements audio, la musique, la parole, etc.
- Données vidéo : Composées de séquences d’images formant des vidéos.
- Données de capteurs : Données recueillies à partir de divers capteurs, tels que les capteurs de température, le GPS, les accéléromètres, etc.
- Données volumétriques : Fait référence aux données qui représentent un espace en trois dimensions et est utilisé notamment dans le contexte de l’imagerie médicale ou des études géospatiales.
- Données de nuage de points : Ensemble discret de points de données dans l’espace. Les points peuvent représenter une forme ou un objet en 3D, chaque position de point ayant son ensemble de coordonnées cartésiennes (X, Y, Z). Les données de nuage de points évaluent généralement les surfaces externes des objets. Ce type de données peut être obtenu, par exemple, avec la photogrammétrie ou le LiDAR. La photogrammétrie est la génération d’un modèle 3D de nuage de points de n’importe quel objet à partir de nombreuses photos numériques du même objet.
Pour gérer et classifier facilement des données de type nuages de points 3D, nous recommandons Pointly GmbH, partenaire de People for AI et qui nous a fourni l’image principale de cet article.
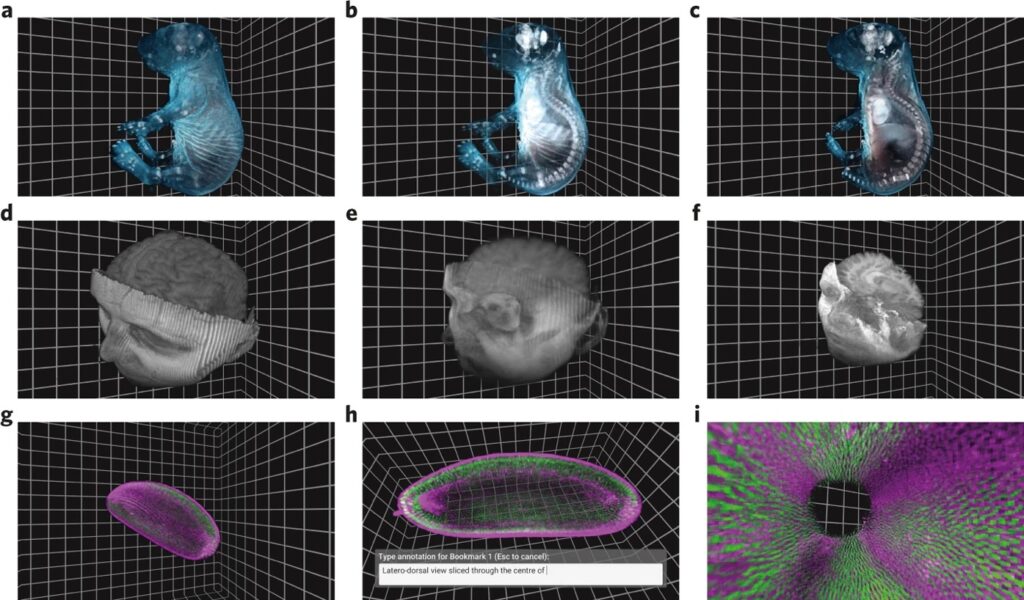
Types d’annotations
Nous pouvons distinguer les différents types d’annotations de données en examinant les différentes tâches d’apprentissage machine. Nous présentons ici les types d’annotations de données dans les domaines suivants : vision par ordinateur (computer vision), traitement du langage naturel et traitement audio.
Vision par ordinateur (CV)
La vision par ordinateur implique de former des modèles d’apprentissage machine pour interpréter les données visuelles, telles que les images ou les vidéos. Pour créer un ensemble de données d’entraînement pour un modèle de vision par ordinateur, il est nécessaire d’annoter les données au préalable. Il existe plusieurs types de tâches d’annotation en vision par ordinateur :
- Classification d’images et de vidéos : classifier des images ou vidéos complètes avec des catégories ou classes. Par exemple, on sépare (en classifiant) les images contenant des animaux et des images n’en contenant pas.
- Détection d’objets : Identifier et localiser les objets dans une image, par exemple en traçant des cadres autour d’eux.
- Détection de points clés : Identifier des points spécifiques d’intérêt dans une image, tels que des repères faciaux ou autres points clés.
- Segmentation d’image : annoter chaque pixel d’une image avec une classe correspondante, souvent utilisée pour la séparation détaillée d’objets.
- Annotation GIS : Identifier et décrire les informations géospatiales, géographiques et aériennes présentes sur les images.
- Annotation 3D :
- Annotation volumétrique 3D : Segmentation sémantique et annotation de cuboïde (ou Bbox 3D) qui fonctionne sur des voxels (c’est-à-dire des pixels 3D).
- Annotation LiDAR : De même, segmentation sémantique 3D et annotation de cuboïde (ou Bbox 3D), mais travaillant sur des nuages de points. Bien que le LiDAR soit une technologie pour créer des nuages de points, tous les nuages de points ne sont pas créés à l’aide du LiDAR (par exemple, la photogrammétrie mentionnée précédemment).
Une fois que l’ensemble de données d’entraînement est annoté, le modèle de vision par ordinateur peut apprendre à partir de ces données pour catégoriser automatiquement les images, détecter les objets, identifier les points clés ou segmenter les images.
Traitement du Langage Naturel (NLP)
Le Traitement du Langage Naturel se concentre sur l’interaction entre les ordinateurs et le langage humain. Les langues écrites et parlées sont naturellement non structurées, et pour extraire des informations et des idées, nous avons besoin de modèles NLP. Pour former des modèles NLP, il est nécessaire d’avoir un ensemble de données d’entraînement avec des données textuelles annotées. Il existe plusieurs tâches d’annotation NLP :
- Reconnaissance optique de caractères (OCR) : Identifier et transcrire le texte à partir d’images, de PDF ou d’autres fichiers. On peut dire que l’OCR commence comme une tâche de computer vision et évolue rapidement vers une tâche NLP. Cela est dû au fait qu’avant de lire et d’annoter les textes (NLP), nous devons reconnaître qu’il y a un texte dans le document (CV).
- Analyse de sentiments : Identifier le sentiment exprimé dans un morceau de texte (par exemple, positif, négatif, neutre).
- Reconnaissance d’entités nommées (NER) : Identifier et classifier les entités (par exemple, noms, lieux, organisations) dans le texte.
- Annotation grammaticale (ou Part-of-Speech) : annoter chaque mot dans une phrase avec sa partie correspondante du discours (par exemple, nom, verbe, adjectif).
Pour les tâches NLP, les annotateurs identifient manuellement les sections pertinentes du texte ou annotent le texte avec des annotations spécifiques, créant un ensemble de données annoté.
Traitement Audio
Le traitement audio implique la conversion de données audio, telles que la parole ou des sons, en un format structuré adapté à l’apprentissage automatique. Le processus peut commencer par la transcription manuelle de l’audio en texte écrit. Après la transcription, il est possible d’ajouter des tags et catégoriser l’audio à des fins spécifiques. Quelques tâches de traitement audio comprennent :
- Reconnaissance vocale (transcription audio) : Conversion du langage parlé en texte écrit.
- Classification sonore : Identification et catégorisation de différents types de sons, comme les bruits de la faune ou les bruits de construction.
Une fois que les données audio sont annotées et catégorisées, elles constituent l’ensemble de données d’entraînement pour les modèles de traitement audio.
Enfin, nous avons l’annotation des Séries Temporelles. Une tâche qui mérite d’être mentionnée, mais qui ne se classe ni en vision par ordinateur, ni en NLP (Traitement Automatique du Langage) ni en traitement audio. Dans l’annotation des séries temporelles, nous attribuons des annotations à différents motifs récurrents ou événements dans les données de séries temporelles, comme la détection d’anomalies ou de cycles récurrents.
Approches pour annoter des données
Nous savons désormais qu’il existe plusieurs types de données et types d’annotations. Quelles sont les manières d’attribuer des annotations aux données ? Et comment réaliser efficacement ces annotations ? Même si l’annotation de données peut sembler un problème trivial au premier abord, il existe de nombreuses façons de réaliser une annotation de données.
Lorsqu’une personne ou une entreprise identifie le besoin d’annoter des données, il existe cinq approches pour le faire. En fonction de la structure du projet IA et de l’allocation des ressources, nous avons :
- L’Annotation interne
- L’externalisation (Outsourcing)
- Main d’œuvre gérée (Managed Workforce)
- Travailleurs indépendants (Freelancers)
- Production participative (Crowdsourcing)
- Annotation programmatique
- Annotation par l’IA
- Données synthétiques (Synthetic data)
Annotation interne (ou in-house)
Lorsque vos propres experts annotent les données. C’est précis mais cela est souvent coûteux en temps et en argent.
Externalisation (Outsourcing)
Dans cette approche, les annotateurs externes à l’entreprise priment.
- Main-d’œuvre gérée (Managed Workforce): Avoir recours à une entreprise spécialisée dans l’annotation de données est, la plupart du temps, un excellent choix. Vous pouvez mobiliser une équipe entière déjà formée à l’annotation de données et disposant également des outils d’annotation nécessaires. Lorsqu’un client choisit de travailler avec People for AI, il choisit de travailler avec une main-d’œuvre gérée.
- Les inconvénients peuvent être la difficulté de mise à l’échelle, le manque de diversité en termes de background/compétences des annotateurs (par exemple, moins de langues seront maîtrisées et il sera plus difficile d’aller chercher des compétences spécifiques).
- Les avantages sont la qualité, la capacité à traiter des tâches plus complexes et de meilleures conditions de travail par rapport aux freelancers et au Crowdsourcing (qui par définition sont des contrats précaires).
- Les inconvénients peuvent être la difficulté de mise à l’échelle, le manque de diversité en termes de background/compétences des annotateurs (par exemple, moins de langues seront maîtrisées et il sera plus difficile d’aller chercher des compétences spécifiques).
- Les avantages sont la qualité, la capacité à traiter des tâches plus complexes et de meilleures conditions de travail par rapport aux freelancers et au Crowdsourcing (qui par définition sont des contrats précaires).
- Travailleurs indépendants (Freelancers): C’est une solution adaptée aux petits projets de courte durée. Mais gérer des freelancers peut prendre du temps. Les freelancers peuvent être compétents, mais ils peuvent manquer d’outils d’annotation, de régularité et cela peut être difficile de mettre l’annotation à l’échelle. Souvent à moyen/long terme, d’autres solutions seront préférées.
- Production participative (Crowdsourcing): C’est une solution rapide et économique car c’est la solution où de nombreuses personnes effectuent de petites tâches simples en ligne. Mais la qualité des annotations peut grandement varier et la gestion des personnes peut être délicate. Par exemple, Recaptcha est un projet célèbre où les gens aident à annoter des données tout en prouvant qu’ils ne sont pas des robots.
Annotation programmatique
C’est une approche automatisée qui utilise des scripts informatiques pour annoter des données, en annotant à partir de règles explicites. C’est une solution rapide mais elle peut nécessiter une vérification humaine pour identifier les problèmes afin de maintenir le bon niveau de qualité. Elle est adaptée aux données non structurées, lorsque ce que nous recherchons est simple et peut être défini par des règles logiques.
Annotation par l’IA (AI Labeling)
Les modèles IA disponibles dans les articles de recherche peuvent suffire pour créer des données annotées ou pour créer un jeu de données pré-annoté (nécessitant quelques corrections et remaniements). Lorsque l’annotation par l’IA conduit à la pré-annotation, des opérateurs humains (annotateurs) doivent ajuster et vérifier le jeu de données pour générer le jeu de données annoté final. Des outils d’annotation intelligents permettent de créer dynamiquement certaines annotations en utilisant des algorithmes courants ou sur étagère (tels que SAM de Meta, par exemple). Ainsi, l’homme et l’IA font équipe pour créer des annotations plus précises et plus rapidement que l’homme ne l’aurait fait seul. D’autres outils permettent même d’entraîner ou d’améliorer un algorithme existant à partir des premières annotations. Cela peut être très utile pour certaines tâches non-complexes.
Données synthétiques (Synthetic data)
Cette méthode consiste à créer de nouvelles données pour le projet à partir de données existantes ou à partir d’une feuille blanche. Cette méthode permet de produire des grandes quantités de données annotées en peu de temps. Cependant, la diversité et la représentativité des données peut être très difficile à atteindre. Créer d’excellents environnements de simulation peut être très coûteux.
Chaque approche a ses avantages et ses inconvénients. Il est donc important de réfléchir à la complexité de la tâche, à la durée, à la taille et aux finalités du projet afin de faire le meilleur choix.
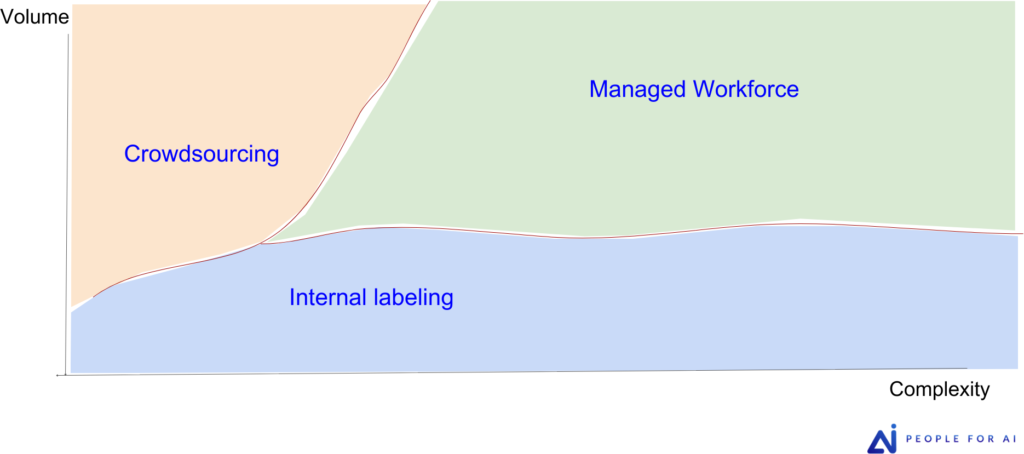
La figure 4 est un outil utile pour vous aider à choisir la main-d’œuvre idéale lors de l’annotation de vos données :
- L’annotation en interne est la plus efficace lorsque le volume de la tâche est faible et que la complexité est importante. La formation d’une équipe d’annotation en interne nécessite beaucoup de ressources, de plus, recruter des annotateurs en interne peut être coûteux dans les pays développés. Cependant, il est plus facile de former et de suivre de près des annotateurs sur des tâches complexes lorsqu’ils se présentent tous les jours aux locaux de l’entreprise.
- Le crowdsourcing est une bonne option lorsque le volume de la tâche est élevé et que la complexité est faible. Ces annotateurs ont souvent un turn-over très important, et ne travaillent pas toujours à plein-temps pour les projets d’annotation des clients. Ces facteurs, additionnés à l’éloignement géographique et culturelle des annotateurs font qu’ils sont difficiles à former sur des tâches non-triviales et qu’il est difficile de conserver une qualité constante dans l’annotation.
- La main-d’œuvre gérée (managed workforce) semble être la meilleure option lorsque vous avez un projet non trivial et un peu volumineux. L’expertise s’accumulera dans l’entreprise d’annotation et au sein de ses équipes dédiées. Cette entreprise d’annotation possède des outils appropriés à une gestion moyen/long terme des projets d’annotation (gestion des équipes, des droits d’accès, pipeline de données, gestion de la qualité, etc.). De plus, l’entreprise d’annotation dédiée pourra mettre en œuvre des méthodes de gestion d’équipe et de qualité pour atteindre vos objectifs.
Pré-annotation & Outils automatiques/semi-automatiques
La pré-annotation et l’annotation automatique/semi-automatique sont des approches qui impliquent l’utilisation de modèles de ML (apprentissage automatique) pour attribuer automatiquement des annotations aux données. Ces outils visent à réduire la charge de l’annotation manuelle et à accélérer le processus d’annotation de données.
Nous commençons par différencier :
- l’annotation automatique/semi-automatique lors de l’annotation ;
- et la fourniture par les clients des pré-annotations.
Lorsque nous recevons une pré-annotation de la part de nos clients, ils utilisent souvent la dernière version de leur(s) modèle(s) pour nous fournir des données pré-annotées. Notre travail consiste alors à vérifier toutes les annotations pour parachever cette annotation.
Lorsque nous parlons d’annotation automatique ou semi-automatique, nous faisons référence au processus par lequel l’outil d’annotation utilisé par l’annotateur, aide à créer l’annotation. Par exemple, lors de la création d’une Bbox (boîte englobante) autour d’un bateau en mer, un outil d’annotation assisté par IA peut créer un masque pour délimiter le bateau plus précisément, ce qui représente une annotation semi-automatique.
Chez People for AI, nous travaillons avec l’annotation semi-automatique tout comme avec des pré-annotations.
Pré-annotations
Certains clients nous fournissent les prédictions de leurs modèles sous forme de pré-annotations. De nombreux outils d’annotation ont la capacité d’importer ces pré-annotations. Ainsi, pour certains projets, nous ne commençons pas de zéro, mais à partir de données pré-annotées.
Il est important de comprendre que, bien que la pré-annotation puisse présenter des avantages en termes de vitesse, une correction manuelle est souvent nécessaire pour garantir la précision et la qualité des données annotées, en particulier pour les tâches ambiguës ou complexes.
Lors de l’usage des pré-annotations, il est nécessaire d’évaluer le gain ou perte de temps de ces pré-annotations. Dans certains cas, corriger des pré-annotations inexactes peut en réalité prendre plus de temps que de commencer le processus d’annotation à partir de zéro, rendant l’effort contre-productif. Cela arrive plus souvent qu’on ne le pense : corriger et supprimer de mauvaises annotations peut être très chronophage. Les annotateurs peuvent également être influencés à tort par les pré-annotations et ainsi fournir un travail de moindre qualité.
« Se concentrer sur des données de haute qualité qui sont annotées de manière cohérente débloquerait et accroîtrait la valeur de l’IA pour des secteurs tels que les soins de santé, la technologie gouvernementale et l’industrie. »“Focusing on high-quality data that is consistently labeled would unlock the value of AI for sectors such as health care, government technology, and manufacturing.”
Andrew Ng, lors d’une interview au MIT sur « Why it’s time for ‘data-centric AI », 2022.
Peut-on échapper à l’annotation des données ?
Notre exploration du domaine de l’IA et des données a révélé le rôle essentiel des services d’annotation de données pour amener l’IA à son plein potentiel. En approfondissant les définitions de l’IA et de l’apprentissage supervisé, la notion d’annotation de données est apparue comme un facteur de réussite dans le processus d’apprentissage. Au cœur de cette idée, on reconnaît l’importance primordiale des données. L’annotation de données, une pratique qui peut sembler simple de prime abord, est un élément fondamental qui donne un contexte compréhensible aux données brutes. Il permet aux systèmes d’IA d’appréhender des concepts complexes et de faire des prédictions éclairées. L’apprentissage supervisé a fait ses preuves grâce à des données annotées de haute qualité, et reproduire ce succès en entreprise dépend de l’attention portée à la qualité de la donnée.
« Les modèles d’AI, tout comme le code informatique associés ne sont plus un problème pour de très nombreuses applications », déclare Andrew Ng. « Maintenant que les modèles ont tant évolué, nous devons faire en sorte que la qualité des données soit à la hauteur. »
Peut-on se passer d’annotation de données ? À mesure que l’IA s’améliore, il arrive un moment où cette amélioration dépend fortement de la qualité des données entrantes. Cela est particulièrement vrai dans l’apprentissage supervisé et c’est une nécessité dans toute quête d’amélioration des modèles d’IA. Dans l’apprentissage supervisé et si on souhaite que l’IA excelle, la réponse est univoque : le succès dépend entièrement d’annotations plus rigoureuses et de données de meilleure qualité.