
Le domaine de la Computer Vision a connu un tournant historique en avril 2023 avec le lancement par Meta du Segment Anything Model (SAM). Ce modèle de fondation « zero-shot » a radicalement transformé la segmentation d’images en permettant de détourer n’importe quel objet sans entraînement spécifique préalable.
Après des mois d’expérimentations sur des jeux de données variés, nous avons identifié ses forces, faiblesses et industrialisé son usage. Aujourd’hui, notre expertise nous permet de déployer deux cas d’usages matures selon les besoins stratégiques de nos clients :
L’assistance interactive : l’IA au service de l’annotateur expert
Dans ce premier scénario, SAM est intégré directement comme un assistant intelligent dans nos outils d’annotation (tels que Kili ou CVAT). L’annotateur pilote l’IA : d’un simple point ou d’une boîte englobante (bbox), il génère un polygone complexe quasi instantanément.

Le pipeline automatisé : la détection d’objet + SAM
Le second cas d’usage, plus industriel, concerne la pré-annotation massive. Ici, SAM intervient après une première étape de détection d’objets effectuée par un modèle de type YOLO (You Only Look Once) ou autre.
Le fonctionnement : Si le client dispose déjà d’un modèle de détection d’objet ou que son cas d’usage est géré par un modèle de type YOLO, les boîtes englobantes servent de « prompts » automatiques pour que SAM génère les masques de segmentation à grande échelle.
L’objectif : Une réduction drastique des coûts et des délais. Nos annotateurs passent alors d’un rôle de « créateur » à celui de « correcteur/validateur » (Human-in-the-loop), ce qui accélère la production de manière exponentielle.
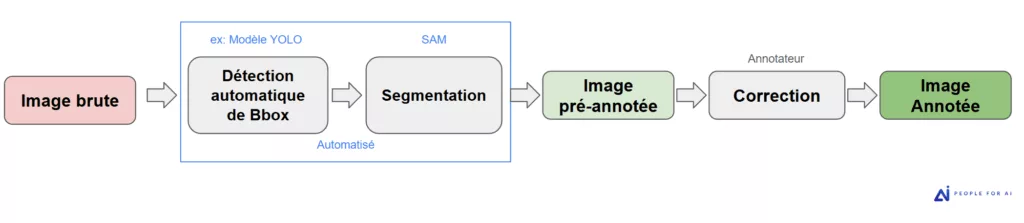
Dans cet article, nous allons détailler quand privilégier l’une de ces approches et explorer les limites techniques de SAM que nous avons identifiées sur le terrain.
1- Dans quels cas SAM est-il le plus performant ?
Bien que SAM soit un modèle « universel », son efficacité maximale s’exprime sur des typologies de données bien précises. Pour nos clients, identifier ces cas d’usage permet de maximiser immédiatement les gains de productivité.
SAM excelle particulièrement dans le cas d’objets aux contours nets et contrastés. Dès que l’objet se détache visuellement de son arrière-plan, SAM produit un masque quasi parfait en un clic ou une boite englobante (bbox) selon les cas.
Ces contrastes peuvent prendre 3 formes :
- Le contraste chromatique (Couleur)
- Le contraste de texture : Un objet rugueux sur une surface lisse. Même si les couleurs sont proches, SAM détecte la rupture de motif.
- Le contraste de luminance (Lumière) : Un objet bien éclairé qui se détache d’une zone d’ombre.
Dans cet exemple, où les objets sont bien nets et contrastés, SAM (utilisé par l’annotateur en mode point ou bbox selon les aliments) ne fait aucune erreur et est très précis.

Sur cet exemple concret, l’utilisation de SAM a permis de finaliser l’annotation en seulement 35 secondes, contre 2 minutes 20 secondes pour un tracé 100% manuel. Ce passage à l’assistance IA divise ainsi le temps d’annotation par 4.
2- Dans quels cas SAM rencontre-t-il ses limites ?
Si SAM est une révolution, il n’est pas une solution « miracle ». Son efficacité repose sur la lisibilité des données : dès que l’image s’éloigne des standards de netteté et de contraste, le modèle perd en fiabilité. En tant qu’experts de l’annotation, notre rôle est d’identifier ces zones de risque pour garantir la qualité finale des datasets de nos clients.
Voici les quatre cas majeurs où SAM rencontre ses limites techniques :
La qualité de l’image source (Flou et Bruit)
Le vieil adage « Garbage in, Garbage out » s’applique ici parfaitement. SAM a besoin de pixels exploitables pour « comprendre » une forme.
Sur des images de drones ou de caméras embarquées, le flou de bougé fait disparaître les bordures. SAM génère alors des masques imprécis qui « débordent » ou « creusent » selon les cas.
De même, une forte compression JPEG crée des artefacts que l’IA peut interpréter par erreur comme des contours.
Sur cette image bien contrastée en couleur mais de mauvaise qualité, on remarque que les contours du masque ne sont pas très précis mais l’ensemble reste très correct et facilement améliorable par l’annotateur en quelques secondes.

L’absence de contraste
SAM ne comprend pas l’objet, il détecte des ruptures de signal (luminance et couleur).
Si l’objet est « fondu » dans son environnement, l’IA ne voit plus bien. Sans contraste de luminance ou de couleur, elle ne peut pas bien isoler la forme.
Dans cet exemple, SAM réalise un masque approximatif de l’arbitre (image floue et moins de contraste sur certaines zones) :

Dans cet exemple, l’annotateur a utilisé SAM en mode point et en mode bbox, on remarque une différence de tracé entre les 2 méthodes avec un meilleur résultat pour la méthode bbox :

Dans ces cas où SAM propose un masque très imparfait, il est souvent plus rapide de refaire le masque à la main que de corriger le masque généré par SAM.
Cette pratique doit être discutée avec le client au préalable car cela implique que certains masques soient tracés via SAM et d’autres manuellement. L’hétérogénéité des tracés peut alors impacter le modèle (voir chapitre suivant).
La sémantique et l’occlusion
SAM identifie des formes, mais il manque de logique contextuelle.
Dans le cas d’objets entremêlés ou d’objets coupés, SAM détecte des formes visibles, mais il ne « comprend » pas l’objet dans sa globalité , ce qui peut engendrer ce genre d’erreurs :


La précision « Pixel-Parfait » sur les textures fines
Le modèle a naturellement tendance à lisser les contours pour produire des masques esthétiques.
Pour des besoins de très haute fidélité (segmentation de cheveux, de fibres textiles ou de végétation fine), ce lissage devient un défaut. L’intervention humaine est alors la seule manière d’obtenir la finesse chirurgicale requise par certains modèles de Deep Learning de pointe.
Dans cet exemple, le contour dentelé de la feuille ainsi que l’extrémité très fine n’ont pas été inclus dans le masque créé par SAM :

3- L’arbitrage entre correction et tracé manuel : un enjeu d’homogénéité
Lorsque SAM propose un masque très imparfait, pour toutes les causes vues dans le chapitre précédent, il est souvent plus rapide et plus précis de supprimer le masque et de le retracer entièrement à la main plutôt que de tenter de corriger des dizaines de points défaillants. Si cette approche permet de gagner en productivité, elle soulève une question méthodologique majeure que nous discutons systématiquement avec nos clients avant le lancement de tout projet : l’homogénéité du dataset.
- Le risque de biais : Un masque généré par SAM (très géométrique, avec un certain lissage) n’a pas tout à fait la même signature visuelle qu’un masque tracé par un humain (souvent plus angulaire).
- L’impact sur l’entraînement : Si un modèle de Deep Learning est entraîné sur un mélange de masques « IA » et « Humains », ces variations peuvent introduire un biais et affecter sa capacité de généralisation.
Selon les exigences de performance du modèle final, nous définissons avec nos clients s’il est préférable de maintenir un flux hybride pour la vitesse, ou de privilégier un tracé 100% manuel sur certaines classes d’objets par exemple pour garantir une cohérence parfaite des données.
4- Le pipeline industriel : l’automatisation par le combo détection d’objet + SAM
Pour les projets nécessitant un passage à l’échelle (scaling) sur des dizaines de milliers d’images, et lorsque la qualité des images le permettent, nous déployons une stratégie de pré-annotation automatisée. Cette approche repose sur une architecture en deux étapes : la détection métier suivie de la segmentation par IA.
Le pré-requis : Un modèle de détection adapté
L’efficacité de ce pipeline dépend de la maturité du projet. Pour que SAM puisse générer des masques automatiquement, il doit recevoir un « prompt » (une instruction). Nous utilisons ici un modèle de détection d’objet, par exemple YOLO (You Only Look Once) :
- Cas A : Le client possède déjà un modèle de détection d’objet entraîné sur ses données métier.
- Cas B : Les objets sont suffisamment standards pour être détectés par un modèle pré-entraîné performant de type YOLO.
Le fonctionnement du flux
Nous avons conçu un pipeline qui maximise la vitesse de traitement sans compromettre la rigueur. Le processus se déroule en trois étapes clés :
- La détection automatique d’objet : nos développeurs déploient le modèle de détection d’objet (ex : YOLO) sur l’ensemble du dataset brut. Ce modèle parcourt chaque image pour identifier les objets et générer des boîtes englobantes (bbox).
- La génération automatisée des masques : nos développeurs font tourner SAM sur les bbox ainsi générées. En utilisant chaque boîte comme un « prompt » (guide de référence), SAM calcule instantanément le masque de segmentation le plus probable pour l’objet détecté.
- La revue experte (Human-in-the-loop) : Une fois ce pré-traitement terminé, nous soumettons ces images pré-annotées à nos équipes d’annotateurs. Leur rôle change de nature : ils ne sont plus là pour créer le tracé de zéro, mais pour agir en tant que contrôleurs et validateurs. Ils corrigent les éventuels débordements, ajustent les contours sur les zones complexes ou fusionnent les segments si nécessaire.
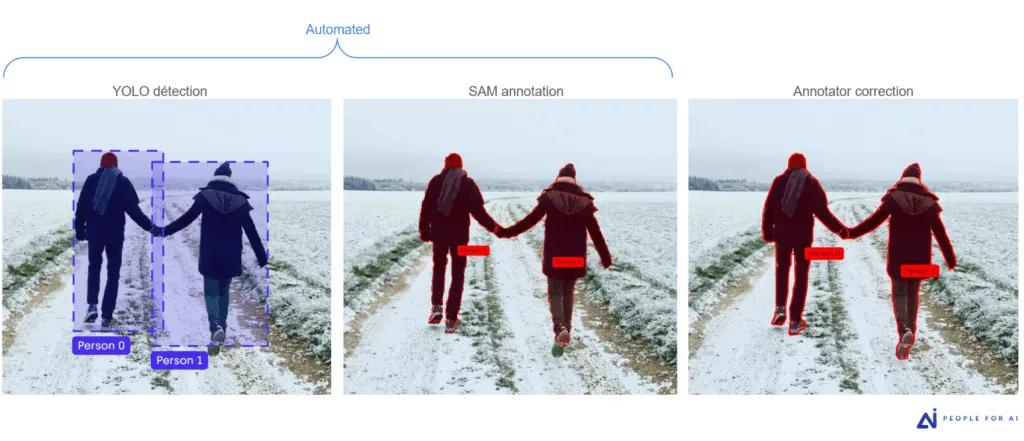
Un gain de productivité massif
Si SAM en mode assistant réduit déjà le temps de travail (nous avons vu dans le 1er chapitre qu’il pouvait considérablement accélérer le temps d’annotation), son intégration dans un flux pré-annoté via YOLO va encore plus loin : sur un projet pour l’un de nos clients, le temps d’annotation par masque a été divisé par deux par rapport au mode assisté classique.
5- Un enjeu majeur : La confidentialité et la sécurité des données (RGPD)
L’utilisation de SAM soulève une question critique pour les projets sensibles (médical, défense, données personnelles identifiables) : où l’image est-elle traitée ?
Pour que l’algorithme de Meta puisse segmenter une image, celle-ci doit obligatoirement être « chargée » sur un serveur équipé de la puissance de calcul nécessaire (GPU).
Les limites du « zéro transfert » : L’utilisation de SAM requiert une infrastructure d’accueil ; il ne peut fonctionner de manière isolée. Si les politiques de sécurité interdisent tout hébergement tiers ou Cloud, le déploiement devient complexe. Une installation locale (ex: CVAT open-source) constitue une alternative, mais elle alourdit la mise en œuvre technique. L’accès via machine virtuelle, souvent nécessaire pour restreindre le téléchargement des données, peut alors générer une latence qui annule les gains de productivité initialement apportés par SAM.
Avant de démarrer un projet, nous validons avec nos clients si le transfert vers les serveurs de nos outils d’annotation sont autorisés. Si la donnée doit rester strictement confinée dans leurs propres systèmes, l’annotation manuelle via un accès distant sécurisé sera le scénario privilégié.
Conclusion : L’IA pour la vitesse, l’humain pour la fiabilité
L’intégration de Segment Anything (SAM) dans nos processus d’annotation marque un tournant majeur : en divisant les temps de production de façon significative, cette technologie permet de répondre aux enjeux de passage à l’échelle avec une réactivité inédite.
Cependant, l’IA ne remplace pas le discernement. Qu’il s’agisse de pallier un manque de contraste, de gérer des occlusions complexes ou de garantir la parfaite homogénéité des jeux de données, l’expertise des annotateurs reste essentielle.
Adopter SAM, c’est choisir la puissance, mais faire appel à People For AI, c’est s’assurer que cette puissance est canalisée par une méthodologie humaine rigoureuse et une gestion sécurisée des données.
Prêt à accélérer vos projets de Computer Vision ? Contactez-nous pour une étude personnalisée de votre dataset et choisissons ensemble le pipeline le plus adapté à vos exigences de qualité.

