Guide complet des techniques d’annotation de données
Découvrez un panorama complet des méthodes d’annotation pour les images, les vidéos et les contenus textuels. Des techniques classiques de vision par ordinateur aux approches avancées pour le NLP et l’entraînement des grands modèles de langage (LLM), explorez l’ensemble des techniques et méthodes clés.

Techniques d'annotation d'images
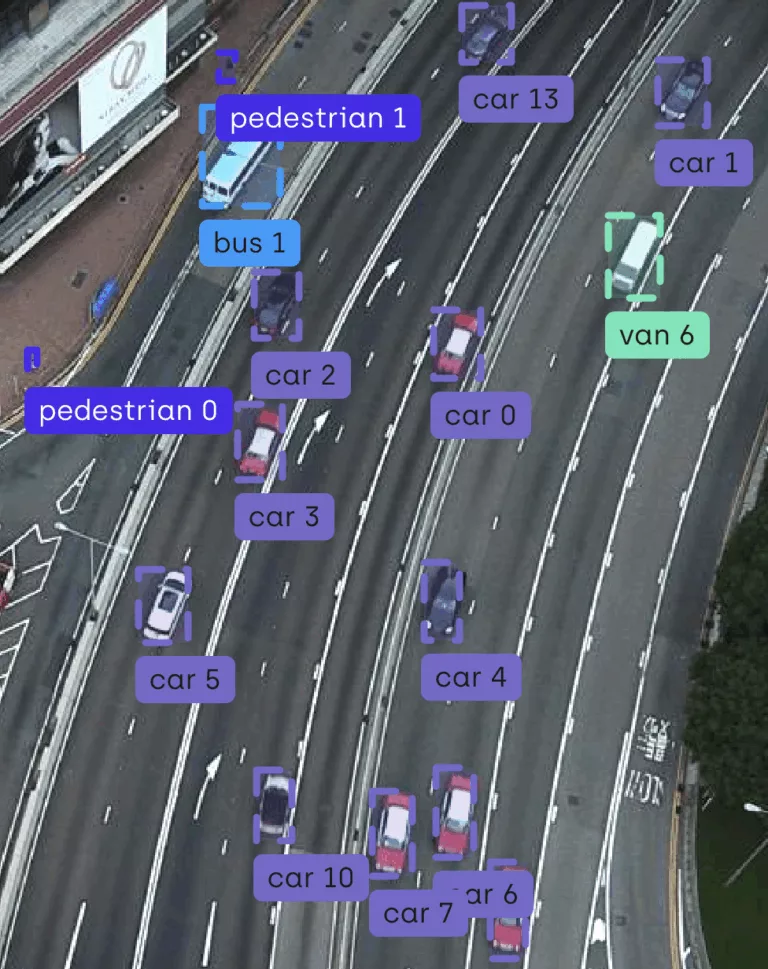
Bounding Box
Délimitation rectangulaire des objets dans l’image
La méthode de la Bounding Box (ou boîte englobante) est l’une des techniques d’annotation d’image les plus couramment utilisées en vision par ordinateur. Elle consiste à tracer un rectangle aligné avec les axes de l’image, de manière à entourer l’objet d’intérêt.
Chaque boîte est généralement définie par ses coordonnées en pixels : la position de son coin supérieur gauche et ses dimensions (largeur et hauteur). Cette technique est particulièrement utilisée pour l’entraînement de modèles de détection d’objets, comme YOLO ou Faster R-CNN.
Bien que simple et rapide à mettre en œuvre, la Bounding Box présente certaines limitations : elle ne capture pas la forme exacte des objets, ce qui peut réduire la précision dans les cas d’objets irréguliers ou partiellement occultés.
→ Pour en savoir plus, voir le cas d’usage dans l’AgTech avec les mauvaises herbes.

Polylignes
Tracé de lignes pour objets allongés ou linéaires
La technique des polylignes consiste à dessiner une série de segments connectés pour suivre la forme d’un objet linéaire, comme des routes, des câbles, ou des bords de trottoirs. Elle est utile lorsque la structure de l’objet ne peut pas être représentée efficacement par une boîte ou un polygone.
Cette méthode est largement utilisée en cartographie et dans la conduite autonome pour détecter les marquages au sol. Elle offre un bon compromis entre précision et simplicité, bien qu’elle ne capture pas la surface pleine de l’objet.

Polygones
Délimitation précise des contours d’un objet
L’annotation par polygones permet de suivre fidèlement la forme d’un objet en plaçant des points aux contours, connectés pour former une surface fermée.
Contrairement aux boîtes, cette méthode offre une haute précision pour des objets aux formes irrégulières ou complexes, comme les bâtiments, les arbres ou les humains.
Elle est largement utilisée dans la segmentation d’image et les applications nécessitant une détection fine. Elle demande cependant plus de temps et d’attention lors de l’annotation.
→ Pour en savoir plus, voir l’étude de cas Foodvisor.

Keypoints
Marquage de points clés sur des objets ou corps
Les keypoints sont utilisés pour annoter des points spécifiques d’intérêt sur un objet, souvent sur le corps humain (ex. : yeux, coudes, genoux). Chaque point est défini par ses coordonnées 2D (ou 3D), ce qui permet de capturer des structures articulées ou des postures.
Cette méthode est centrale en analyse de mouvement, reconnaissance de gestes ou détection de poses. Elle est légère en données mais requiert une grande précision dans le placement des points.
→ Pour en savoir plus, voir le cas d’usage dans le sport avec Reap Analytics, qui a été fait avec des BBoxs mais aussi avec des Keypoints/Squeletons

Masques
Segmentation pixel-par-pixel pour une importante précision
L’annotation par masques consiste à assigner une étiquette à chaque pixel d’une image afin de délimiter précisément la zone occupée par un ou plusieurs objets. Contrairement aux bounding boxes ou polygones, les masques offrent une segmentation fine, essentielle pour des applications comme la segmentation d’image, la réalité augmentée, ou la médecine.
On distingue principalement deux types de segmentation via masques :
La segmentation sémantique : chaque pixel est classé selon une catégorie d’objet (ex. : « route », « piéton », « ciel »), sans distinguer les instances individuelles. Tous les piétons de l’image, par exemple, partageront le même label.
La segmentation par instance (masques d’instances) : elle combine détection et segmentation, en identifiant chaque objet individuellement, même s’ils appartiennent à la même classe. Ainsi, chaque piéton se voit attribuer un masque propre, avec une identité distincte.
Cette méthode est la plus précise mais aussi la plus coûteuse en annotation manuelle. Elle est souvent assistée par des outils semi-automatiques ou des réseaux de neurones spécialisés comme Mask R-CNN.
→ Pour en savoir plus, voir le cas d’usage avec Newcastle University pour l’annotation de masques au niveau microscopique.
La majorité des techniques utilisées pour annoter des images — comme les bounding boxes, les polygones, les keypoints ou les masques de segmentation — peuvent être appliquées image par image au sein d’une séquence vidéo. C’est cette continuité temporelle qui introduit des défis spécifiques, mais aussi des opportunités de gain de temps via l’interpolation ou le suivi automatique.
Voici les techniques d’annotation de vidéos qui sont propres au format vidéo.
Techniques propres à l'annotation de vidéos

Annotation Multi-Modale
Synchronisation des données visuelles et sonores
L’annotation multimodale exploite plusieurs sources de données simultanément, notamment l’image et le son. Un exemple courant est la transcription audio/vidéo synchronisée, qui consiste à associer un texte (paroles, bruitages, sons) à des moments précis de la vidéo. Cela permet de créer des sous-titres, des annotations de dialogue, ou d’identifier des événements sonores.
Ce type d’annotation est essentiel dans les domaines du traitement du langage naturel, de l’accessibilité, ou de l’analyse de vidéos complexes où le contenu audio est aussi important que l’image.
→ Pour en savoir plus, voir le cas d’usage avec la modération de contenu vidéo.

Interpolation
Automatisation partielle à partir d’images clés
L’interpolation est une technique qui permet de réduire le temps d’annotation vidéo en annotant uniquement certaines images clés (keyframes), tandis que les annotations intermédiaires sont générées automatiquement. Par exemple, en plaçant une bounding box sur une image au début et une autre quelques frames plus loin, le système peut interpoler leur position entre les deux.
Cette méthode est utile pour les objets en mouvement fluide et permet d’accélérer le processus d’annotation tout en conservant une bonne précision. Elle est souvent couplée à des corrections manuelles lorsque les déplacements ne sont pas linéaires ou lorsque des occlusions surviennent.
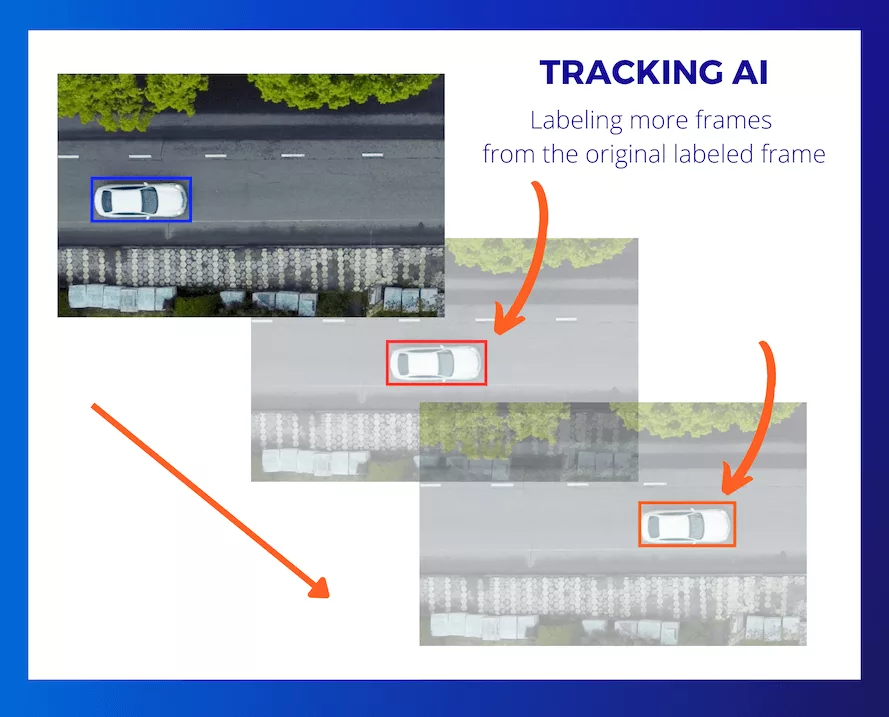
Tracking IA
Suivi automatique des objets au fil du temps
Le tracking basé sur l’intelligence artificielle consiste à suivre automatiquement un objet annoté dans une vidéo à l’aide d’algorithmes de vision par ordinateur. Après une annotation initiale, le système détecte et suit l’objet dans les frames suivantes, en mettant à jour sa position, sa taille ou sa forme.
Cette méthode est particulièrement efficace dans des vidéos où les objets se déplacent de manière cohérente. Ce type d’annotation réduit considérablement l’effort humain, mais nécessite souvent une vérification manuelle pour éviter les erreurs de suivi.

Séquençage
Segmentation temporelle des scènes et des comportements
Le séquençage vidéo regroupe deux types d’annotation temporelle :
Le changement de scène ou segmentation temporelle, qui consiste à repérer les transitions entre différentes séquences visuelles, souvent utilisées pour découper une vidéo en unités logiques (ex. : nouveaux plans, nouveaux contextes).
L’annotation des actions ou comportements, qui vise à étiqueter des événements spécifiques (ex. : marcher, courir, sauter) sur une plage temporelle. Ces annotations peuvent se superposer à des objets ou à des personnes, et permettent de décrire dynamiquement le contenu d’une vidéo, notamment dans les domaines du sport, de la surveillance ou de l’analyse comportementale.
Types d'annotations appliquées au texte et aux documents (NLP et LLM)

Annotation visuelle de documents textuels
Marquage spatial pour la compréhension de documents
Utilisation de bounding boxes pour localiser des zones de texte, de polylignes pour tracer les structures tabulaires ou graphiques, et d’annotations mixtes pour relier le contenu textuel à sa mise en page (ex. OCR structuré, parsing de PDF).
→ Pour en savoir plus, voir l’étude de cas concernant l’Intelligent Document Processing

Analyse de sentiment et de la subjectivité
Annotation du ton, de la polarité et de l’intensité de l’opinion
Marquage de la valence émotionnelle d’un texte (positif, négatif, neutre), de son degré d’enthousiasme ou de subjectivité. Peut inclure des nuances comme la colère, la joie, la surprise, ou un score d’intensité.
Cela peut aussi avoir rapport avec le ton de la personne et si ce qui est dit peut être réprimandé par la loi.
→ Pour en savoir plus, voir le cas d’usage avec la modération de contenu vidéo.

Annotation morpho-syntaxique et reconnaissance d’entités nommées (POS Tagging & NER)
Identification des catégories grammaticales et des entités spécifiques
POS Tagging : catégoriser chaque mot selon sa fonction grammaticale (nom, verbe, adjectif, adverbe, etc.).
NER : détecter et classer les entités nommées (personnes, organisations, lieux, dates, etc.).
EXAMPLE :
Phrase : Marie a envoyé un email à Paul hier.
POS : Marie (Nom propre), a (Verbe auxiliaire), envoyé (Verbe), un (Déterminant), email (Nom), à (Préposition), Paul (Nom propre), hier (Adverbe).
NER : Marie (Personne), Paul (Personne).

Segmentation et annotation syntaxique/sémantique
Découpage et structuration linguistique
Segmentation en phrases, paragraphes ou unités linguistiques pertinentes, suivi de l’analyse de la structure syntaxique (parsing en constituants ou dépendances), de la désambiguïsation lexicale et de l’annotation des rôles sémantiques.
EXEMPLE
Parsing en constituants :
La femme a vu l’homme avec une longue-vue
→ [La femme [a vu [l’homme] [avec [une longue-vue]]]]
ou
→ [La femme [a vu [l’homme [avec [une longue-vue]]]]]
Analyse en dépendances :
Le chat noir dort sur le canapé.
dort→ racinechat→ sujet dedortnoir→ adjectif dechatsur→ complément dedortcanapé→ objet desur

Annotation de relations
Repérage des liens entre expressions ou événements
Identification des expressions qui désignent la même entité dans un texte (co-référence), ainsi que d’autres liens sémantiques (cause-effet, condition, opposition, inclusion…).
EXEMPLES
- Relation cause-effet
La pluie a provoqué des inondations.
Relation : cause (pluie) → effet (inondations).
- Relation condition
Si le trafic est fluide, nous arriverons à l’heure.
Relation : condition (trafic fluide) → résultat (arriver à l’heure).
- Relation d’opposition
Il aime la mer, mais elle préfère la montagne.
Relation : opposition (mer ↔ montagne).
- Relation d’appartenance
Paris est la capitale de la France.
Relation : capitale de la France → Paris

Annotation pour l’entraînement des grands modèles de langage
Préparation des données pour le fine-tuning et l’alignement
RLHF (Reinforcement Learning from Human Feedback) : annotation qualitative ou comparative des réponses générées par un modèle pour optimiser son comportement.
Supervised Fine-Tuning (SFT) : création de paires prompt / réponse ou de jeux de données supervisés pour entraîner un modèle.
EXEMPLES
- Annotation de préférence pour le RLHF
- But : Améliorer le comportement du modèle en notant ou en classant ses réponses.
- Prompt : Explique la gravité à un enfant de 6 ans.
Réponse A : La gravité est une force invisible qui fait tomber les choses vers la Terre. ✅ (plus claire et adaptée)
Réponse B : La gravité est l’accélération d’un corps proportionnelle à la masse et inversement proportionnelle au carré de la distance. ❌ (trop technique)
→ Annotation : Marquer A comme préférable à B.
- Fourniture de paires prompt / réponse correctes pour l’entraînement du modèle pour le SFT
Prompt : Donne-moi trois synonymes du mot “heureux”
Réponse attendue : joyeux, content, satisfait
Des annotations de qualité avec un engagement juste
ANNOTATEURS EN CDI
Après la période d'essai, nous n'engageons que des annotateurs avec des contrats CDI Nous avons professionnalisé le métier d'annotateur en sélectionnant des personnes rigoureuses et patientes.
DES EXPERTS À PORTÉE DE MAIN
Nous disposons d'une équipe expérimentée de gestion de projet, composée d'anciens data scientists, capable de mener à bien les projets les plus complexes.
POLITIQUE RSE ET SOCIALE
Nous travaillons en étroite collaboration avec Le Relais Madagascar, une entreprise qui vise à réinsérer socialement des personnes au parcours difficile. 20% de notre effectif ont surmonté d'importantes difficultés de vie.
Ils nous font confiance




