The aim of this article is to clarify the context and operation of data labeling, as well as its key features. Curious, isn’t it? Let’s go! Our article is divided into four sections:
- Context on AI & Data Labeling: Key concepts’ definitions
- Importance of having good data: Data-centric AI
- Data labeling
- Can we avoid data labeling?
Context on AI & Data Labeling
I always believe it’s better to start an analysis by understanding the big picture and structuring the main concepts. So before we delve into the specifics of data labeling, let’s recognize where this field of study is found.
We are in the dimensions of Artificial Intelligence (AI), which the Editors of Encyclopaedia Britannica define as: “the ability of a digital computer or computer-controlled robot to perform tasks commonly associated with intelligent beings”, given that intelligence means that “must include the ability to adapt to new circumstances.”
More specifically now, the Editors of Encyclopaedia Britannica define Machine Learning (ML) as “the method to train a computer to learn from its inputs but without explicit programming for every circumstance.” Machine learning helps a computer to achieve artificial intelligence.
These methods, or algorithms, to train a computer to learn (ML) can be either supervised or unsupervised.
Supervised and unsupervised learning
Unsupervised learning involves algorithms analyzing unlabeled data to try to identify inherent patterns, structures, or relationships among data points. Unlike supervised learning, unlabeled data have no predefined outputs for the algorithm to learn from. Instead, the algorithm seeks to find similarities or groupings within the data on its own, such as clustering similar data points together based on their characteristics. Envision an explorer venturing into uncharted territory without a map.
Supervised learning algorithms learn by using labeled examples where input data is paired with corresponding desired outputs. This enables the algorithm to understand patterns and relationships between inputs and outputs, which it can then apply to new, unseen data. Imagine a teacher guiding a student with solutions to problems.
Supervised learning algorithms have many applications in real life. For instance, face detection, text categorization, stock predictions, spam detection, amongst others. Later, we will dive into some of them.
When working with supervised learning algorithms, we need the “answers to the problem” – that is, we need the data to have an adequate label that categorizes it properly. But, unstructured data doesn’t come with labels naturally (e.g. images, videos, sentences, i.e. when we take a picture, it doesn’t show which elements are dogs or cats). For that, we need data labeling.
Data labeling, or data annotation, is the process of adding meaningful and informative labels to raw data (e.g. images, text files, videos, etc.) to provide context so that a machine learning model can learn from it. Data labeling is required for a variety of use cases including computer vision, natural language processing, and speech recognition.
Importance of having good data
As one of our partners, Kili Technology, once said, “Let’s get straight to the point: the effectiveness of machine learning models relies solely on the quality of the data used for their training.” We believe that to achieve AI success, a company needs high-quality labeled data to train its model.
The use of poorly labeled, low quality data when training a model is detrimental to its user. But how big is the impact?
- A 2016 study by IBM found that poor data quality costs $3.1 trillion from the U.S. economy annually due to lower productivity, system outages and higher maintenance costs, to name only a handful of the bad outcomes that result from poor data quality.
- The research firm IDC estimated the size only of the big data market to be $136 billion per year, worldwide, in 2016.
Data-centric AI
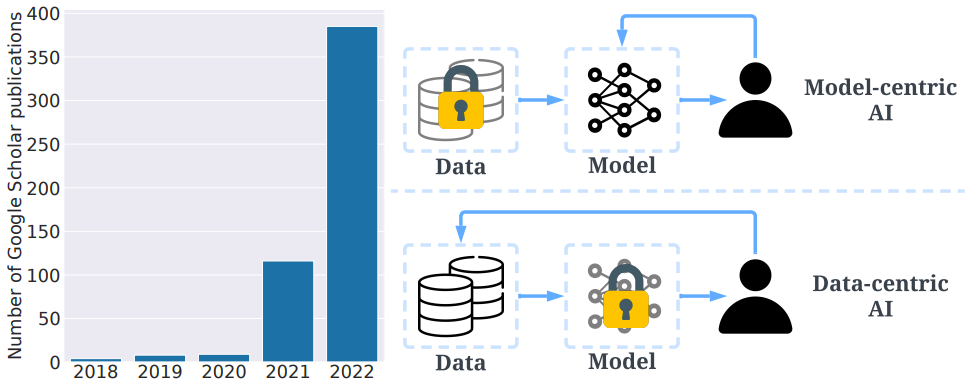
This perception, that poor data quality damages business value, has gained more and more strength in recent years. It’s due especially to great thinkers such as Andrew Ng advocating data-centric AI approaches and raising awareness in the scientific field. He defines data-centric AI as “the discipline of systematically engineering the data needed to build a successful AI system.” AI systems need both code and data, and Andrew Ng at a 2022 EmTech Digital conference hosted by MIT Technology Review, that “all that progress in algorithms means it’s actually time to spend more time on the data,”
That line of thinking believes that model-centric AI is based on the goal of “producing the best model for a given dataset”, whereas data-centric AI is based on the goal of “systematically & algorithmically producing the best dataset to feed a given ML model.”
”My view is that if 80% of our work is data preparation, then ensuring data quality is the important work of a machine learning team.”
Andrew Ng, who was involved in the rise of massive deep learning models trained on vast amounts of data, but now is preaching small-data solutions.
When we consider the cost-effectiveness of a data-centric approach, it is clear that the initial investment in quality data labeling can lead to substantial long-term benefits, as the accuracy and quality of the data directly influences the effectiveness of the AI system. This synergy between data-driven AI and data labeling is in line with the notion that a solid foundation of quality data is fundamental to AI success.
Ok, so now we know that we need data labeling to work with supervised learning algorithms, which are a type of machine learning algorithm that enables solving many problems. We also understood the need to focus on high quality data. Now, let’s start delving into data labeling.
Data labeling
In the context of data labeling, there are some elements we must consider to conceive this domain. If data labeling is adding meaning to raw data it means that we have multiple:
- Types of data that we can label
- Types of labels that we can add to data
- Approaches to label a data
- Pre-Labeling & Automatic/Semi-Automatic tools
Types of data
Data types refer to the format and nature of the data being labeled. In the context of data labeling for machine learning, the data can be categorized into various types, such as:
- Text Data: Includes text documents, PDF documents, social media posts, emails, articles, etc.
- Image Data: Comprises visual content in the form of images or frames from videos.
- Audio Data: Includes audio recordings, music, speech, etc.
- Video Data: Consists of sequential frames that form videos.
- Sensor Data: Data collected from various sensors, such as temperature sensors, GPS, accelerometers, etc.
- Volumetric Data: Refers to data that represents a three-dimensional space and is used especially in the context of medical imaging or geospatial studies.
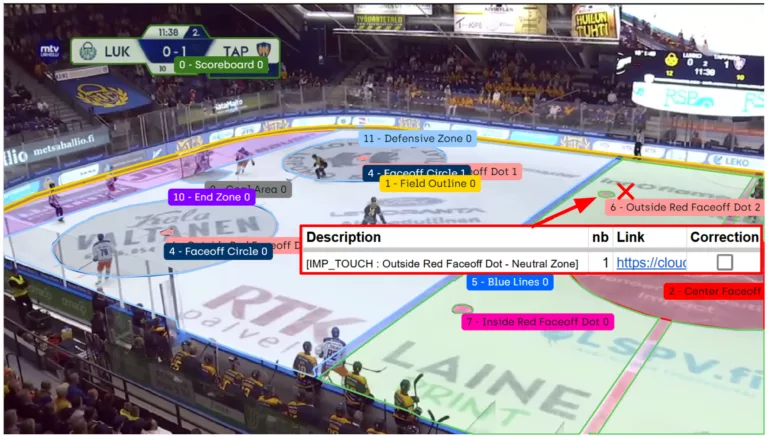
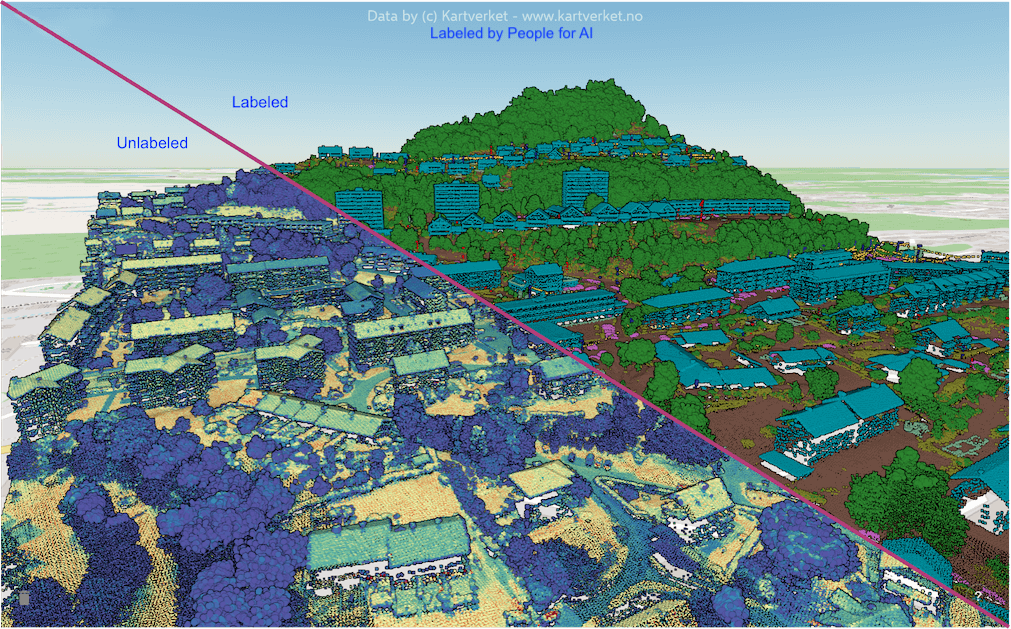
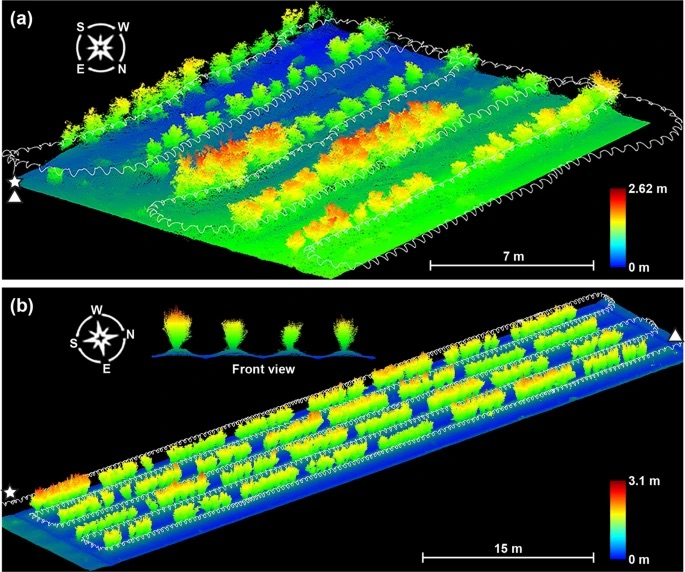
- Point Cloud Data: Discrete set of data points in space. The points may represent a 3D shape or object, each point position has its set of Cartesian coordinates (X, Y, Z). Point cloud data usually assess the external surfaces of objects. This type of data can be obtained, for example, with photogrammetry or LiDAR. Photogrammetry is the generation of a 3D point cloud model, known as the as-built model, of any object from many digital pictures of the same object.
To manage and classify data in 3D point clouds, we would like to recommend Pointly GmbH, partner of People for AI and the one who provides us with the image on top of this article.
Types of labels
We can view types of data labeling in the context of different machine learning tasks. Here, we are assessing the types of labels in three applications: computer vision, natural language processing and audio processing.
Computer vision (CV)
Computer Vision involves training machine learning models to interpret and understand visual data, such as images or videos. To create a training dataset for a computer vision system, you need to label the data with relevant annotations. There are several types of computer vision labeling tasks:
- Image and Video Classification : Labeling images into different categories or classes. For example, classifying images as product images or lifestyle images.
- Object Detection: Identifying and localizing objects within an image by, for example, drawing bounding boxes around them.
- Key Point Detection: Identifying specific points of interest within an image, such as facial landmarks or keypoints.
- Image Segmentation: Labeling each pixel in an image with a corresponding class, often used for detailed object separation.
- GIS Annotation: Identifying and describing geo-spacial, geographic and aerial information present on images.
- 3D Annotation:
- 3D Volumetric Annotation : Semantic segmentation and cuboid annotation (or 3D Bbox) which work on voxels (ie. 3D pixels).
- LiDAR Annotation: The same, 3D semantic segmentation and cuboid annotation (or 3D Bbox), but working on point clouds. Although LiDAR is a technology for creating point clouds, not all point clouds are created using LiDAR (e.g. photogrammetry previously mentioned).
Once the training dataset is labeled, the computer vision model can learn from this data to automatically categorize images, detect objects, identify key points, or segment images.
Natural Language Processing (NLP)
Natural Language Processing focuses on the interaction between computers and human language. Written and spoken languages are naturally unstructured, and to extract information and insights, we need NLP models. To train NLP models, you need to create a training dataset with labeled text data. There are various NLP labeling tasks:
- Optical Character Recognition (OCR): Identifying and transcribing text from images, PDFs, or other files. We can say that OCR starts as a CV task and fastly evolves to a NLP one. That is due to the fact that before reading and labeling the texts (NLP), we need to recognize that there’s a text in the document (CV).
- Sentiment Analysis: Identifying the sentiment expressed in a piece of text (e.g., positive, negative, neutral).
- Named Entity Recognition (NER): Identifying and classifying entities (e.g., names, places, organizations) in the text.
- Part-of-Speech (or Grammatical) Tagging: Labeling each word in a sentence with its corresponding part of speech (e.g., noun, verb, adjective).
For NLP tasks, human annotators manually identify important sections of text or tag the text with specific labels, creating a labeled dataset that the NLP model can learn from.
Audio Processing
Audio Processing involves converting audio data, such as speech or sounds, into a structured format suitable for machine learning. The process starts with manually transcribing the audio into written text. After transcription, you can add tags and categorize the audio for specific purposes. Some audio processing tasks include:
- Speech-to-Text (audio transcription): Converting spoken language into written text.
- Sound Classification: Identifying and categorizing different types of sounds, like wildlife noises or building sounds.
Once the audio data is labeled and categorized, it becomes the training dataset for audio processing models.
Finally, we have Time Series Labeling. A task that deserves to be mentioned but doesn’t classify as NLP, audio processing and computer vision. In time series labeling we assign labels to different patterns or events in time series data, such as anomaly detection.
Approaches to label a data
We know that there are multiple types of data and types of labels, but how can we assign a label to a data? And effectively do data labeling? Data labeling is really important when making a strong ML model and, even though it might seem straightforward, there are many ways to do so.
When someone or a company decides to obtain labeled data, usually there are five approaches to do so. Varying according to the choice of how the AI project is structured and its allocation of resources, we have:
- Internal (or in-house) labeling
- Outsourcing: Managed Workforce, Freelancers, Crowdsourcing
- Programmatic labeling
- AI Labeling
- Synthetic data
Internal (or in-house) labeling
When your own experts label the data. It’s accurate but takes time and works best for big companies with lots of resources.
Outsourcing
In this approach, one looks for labelers from outside of the company. We have three types of outsourcing: managed workforce, freelancers and crowdsourcing.
- Managed Workforce: Hiring a data labeling company to do the job is, most of the time, the optimal choice. You can hire a whole team that’s already trained and prepared and also possesses the tools ready. Advantages are quality, tackling more complex tasks, better work conditions. Drawbacks can be scalability and lack of variety in terms of the background and skills of the annotators (e.g. languages, specific competences, etc.). When a client chooses to work with People for AI, they are choosing to work with a managed workforce.
- Freelancers: This is good for big projects that don’t last long. But handling freelancers can take time. Usually freelancers can be skillful, but they might lack labeling tools, regularity, and scalability. It is not a long-term solution.
- Crowdsourcing: This is fast and cheap because many people do small and trivial tasks online. But the quality and management can be tricky. For example, Recaptcha is a famous project where people help label data while proving they’re not bots.
Programmatic labeling
This is an automated approach that uses computer scripts to label data, by labeling from explicit rules. It’s fast but needs humans to check for problems to keep the right level of quality. It’s specific to unstructured data, when what we are searching is simple and can be defined in a few logical rules.
AI Labeling
On-the-shelf AI models that can be found in research papers may suffice as a first step for data annotation. AI labeling leads to pre-labeling, where humans adjust and verify this pre-labeled dataset to actually generate the labeled dataset. Smart labeling tools allow you to dynamically create some labels using common algorithms (Meta’s SAM, for example). Some tools even allow you to train or improve an existing algorithm from the first labels. It can be really useful for some easier tasks.
Synthetic data
This way involves creating new project data from existing data. It’s quick and makes good data, but needs great simulation environments and fine tuning which can be expensive. This is not a method to label the data but rather one to create labeled data from scratch.
Each approach has its pros and cons, so it’s important to ponder the complexity of the task and the duration, size and scope of the project carefully in order to make the best choice.
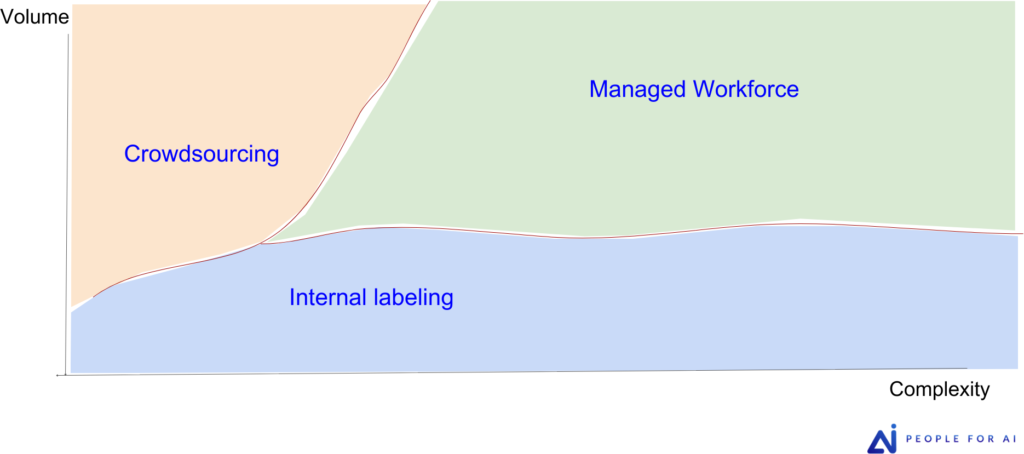
Figure 4 is a useful tool to help you choose the ideal workforce when labeling your data. We can see that in-house annotation works best when the volume of the task is low and the complexity increases, as forming an in-house labeling team is resource-intensive and expensive. Crowdsourcing is a good option when the volume of the task is high and the complexity is low, since it is a mass job and the annotators are not highly trained. The managed workforce seems to be the best option when you have a complex and voluminous project, because here you have a company that has the know-how, trained labelers and the appropriate tools.
Pre-Labeling & Automatic/Semi-Automatic tools
Pre-labeling and automatic or semi-automatic labeling are approaches which involve using machine learning algorithms or pre-existing models to automatically assign labels to the data. These tools aim to reduce the manual labeling burden and accelerate the data labeling process.
We start by differentiating between automatic or semi-automatic labeling and getting pre-labels from clients. When we get pre-labeling from our customers, they use the latest version of their model to provide us with labeled data. The work here involves checking all the annotations and defining the appropriate label, making corrections. When we say automatic or semi-automatic labeling, we are referring to the process in which the labeling tool, which assists the labeler in the annotation process, is the one who creates the label. For example, when drawing a bounding box on a boat at sea, the AI tool will create a mask to delimit the boat from the sea, which is a semi-automatic label.
At People for AI, we work with semi-automatic labeling as well as with pre-labels.
Pre-labeling
Some clients provide us with predictions from their models as pre-labels. The ability to import these pre-labels is a feature of many labeling tools. Therefore, in some projects we don’t start from scratch, but from pre-labels.
It’s important to understand that while pre-labeling has its merits in speeding up processes, human annotation is often necessary to ensure the accuracy and quality of the labeled data, especially for complex tasks or ambiguous data. It can serve as a worthy foundation, but it often requires human intervention for refinement.
Indeed, pre-labeling contributes to faster progress when it saves time in comparison to starting a new process. However, it is worth considering the potential pitfalls of low-quality pre labels. In some cases, correcting inaccurate pre-labels can actually consume more time than starting the labeling process from scratch, making the effort counterproductive. This happens more often than we can believe, correcting and deleting bad labels can be time-consuming. Labelers can also be wrongly influenced by the pre-labels and deliver a lower-quality work.
“Focusing on high-quality data that is consistently labeled would unlock the value of AI for sectors such as health care, government technology, and manufacturing.”
Andrew Ng, in a MIT interview on “Why it’s time for ‘data-centric AI’” , 2022.
Can we avoid data labeling?
Our investigation of the domain of AI and data has revealed the essential role of data annotation services in driving AI to its full potential. As we delved deeper into the definitions of AI and supervised learning, the notion of data labeling emerged as a success factor in the learning process. Central to this idea is the recognition of the paramount importance of data. Data labeling, a practice that may seem straightforward, is in fact the fundamental element that gives contextual understanding to raw data, enabling AI systems to uncover complex patterns and make informed predictions. Today, what works well is supervised learning, relying on labeled output examples for quality.
“The model and the code for many applications are basically a solved problem,” says Ng. “Now that the models have advanced to a certain point, we got to make the data work as well.”