Complete guide to data annotation techniques
Discover a complete overview of annotation methods for images, videos, and text content. From classic computer vision techniques to advanced approaches for NLP and the training of large language models (LLMs), explore all the key techniques and methods.

Image Annotation Techniques
Rectangular outline of objects in the image
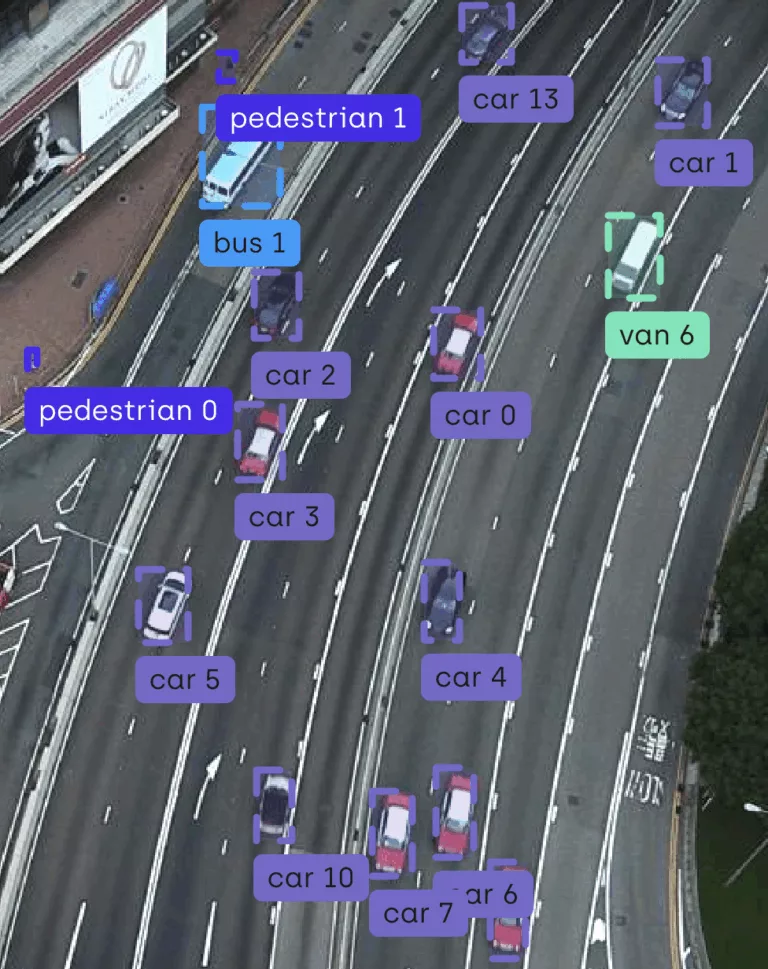
The Bounding Box method is one of the most commonly used image annotation techniques in computer vision. It consists of drawing an axis-aligned rectangle to enclose the object of interest. Each box is typically defined by its pixel coordinates: the position of its top-left corner and its dimensions (width and height). This technique is especially used for training object detection models, such as YOLO or Faster R-CNN. While simple and quick to implement, the Bounding Box method has some limitations: it doesn’t capture the exact shape of objects, which can reduce accuracy in cases of irregular or partially occluded objects.
→To learn more, see the use case in AgTech with weeds.

Polyline
Tracing Lines for Elongated or Linear Objects
The polyline technique involves drawing a series of connected line segments to trace the shape of a linear object, such as roads, cables, or the edges of sidewalks. It is useful when the object’s structure cannot be represented effectively by a box or a polygon.
This method is widely used in mapping and autonomous driving for detecting road markings. It offers a good compromise between precision and simplicity, although it does not capture the full surface area of the object.
Cette méthode est largement utilisée en cartographie et dans la conduite autonome pour détecter les marquages au sol. Elle offre un bon compromis entre précision et simplicité, bien qu’elle ne capture pas la surface pleine de l’objet.

Polygon
Precise Delineation of Object Contours
Polygon annotation involves accurately tracing the shape of an object by placing a series of points along its outline, which are then connected to form a closed surface.
Unlike bounding boxes, this method offers high precision for objects with irregular or complex shapes, such as buildings, trees, or humans.
It’s widely used in image segmentation and applications requiring fine-grained detection. However, it is more time-consuming and labor-intensive than other methods.
→ To learn more, see the Foodvisor case study.

Keypoints
Marking Key Points on Objects or Bodies
Keypoints are used to annotate specific points of interest on an object, often on the human body (e.g., eyes, elbows, knees). Each point is defined by its 2D (or 3D) coordinates, which allows for the capture of articulated structures or postures.This method is central to motion analysis, gesture recognition, and pose detection. It’s data-light but requires high precision in the placement of the points.
→ To learn more, see the use case in sports with Reap Analytics, which was done with both Bounding Boxes and Keypoints/Skeletons.

Masks
Pixel-by-Pixel Segmentation for High Accuracy
Mask annotation involves assigning a label to each pixel in an image to precisely delineate the area occupied by one or more objects. Unlike bounding boxes or polygons, masks offer fine-grained segmentation, which is essential for applications like image segmentation, augmented reality, or medicine.
There are two main types of segmentation using masks:
–Semantic Segmentation: Each pixel is classified according to an object category (e.g., “road,” “pedestrian,” “sky”), without distinguishing between individual instances. All pedestrians in the image, for example, will share the same label.
–Instance Segmentation (Instance Masks): This technique combines detection and segmentation by identifying each object individually, even if they belong to the same class. Thus, each pedestrian is assigned its own unique mask with a distinct identity.
This method is the most accurate but also the most expensive for manual annotation. It is often assisted by semi-automatic tools or specialized neural networks like Mask R-CNN.
→ To learn more, see the case study with Newcastle University for annotating masks at a microscopic level.
Most image annotation techniques—such as bounding boxes, polygons, keypoints, or segmentation masks—can be applied frame-by-frame within a video sequence. This temporal continuity introduces specific challenges but also opportunities for time-saving through interpolation or automatic tracking.
Here are the video annotation techniques that are specific to the video format.
Techniques specific to video annotation

Multimodal Annotation
Synchronizing Visual and Audio Data
Multimodal annotation leverages multiple data sources simultaneously, particularly image and sound. A common example is synchronized audio/video transcription, which involves associating text (speech, sound effects, noises) with specific moments in a video. This allows for the creation of subtitles, dialogue annotations, or the identification of sound events.
This type of annotation is essential in fields such as natural language processing, accessibility, or the analysis of complex videos where audio content is just as important as the image.
→ To learn more, see the use case with video content moderation.

Interpolation
Partial Automation from Keyframes
Interpolation is a technique that reduces video annotation time by annotating only certain keyframes, while the intermediate annotations are generated automatically. For example, by placing a bounding box on an image at the beginning and another a few frames later, the system can interpolate their position between the two.
This method is useful for smoothly moving objects and helps to speed up the annotation process while maintaining good accuracy. It is often combined with manual corrections when movements are not linear or when occlusions occur.
AI Tracking
Automatic Object Tracking Over Time
AI-based tracking automatically follows an annotated object throughout a video using computer vision algorithms. After an initial annotation, the system detects and tracks the object in subsequent frames, updating its position, size, or shape.
This method is particularly effective in videos where objects move consistently. This type of annotation significantly reduces human effort but often requires manual verification to prevent tracking errors.

Sequencing
Temporal Segmentation of Scenes and Behaviors
Video sequencing encompasses two types of temporal annotation:
- Scene change or temporal segmentation, which involves identifying transitions between different visual sequences. This is often used to break down a video into logical units (e.g., new shots, new contexts).
- Action or behavior annotation, which aims to label specific events (e.g., walking, running, jumping) over a specific time range. These annotations can be applied to objects or people, and they allow for the dynamic description of video content, particularly in sports, surveillance, or behavioral analysis.
Types of Annotations Applied to Text and Documents (NLP and LLMs)

Visual Annotation of Textual Documents
Spatial Marking for Document Understanding
Using bounding boxes to locate text areas, polylines to trace tabular or graphical structures, and mixed annotations to link textual content with its layout (e.g., structured OCR, PDF parsing).
→ To learn more, see the case study on Intelligent Document Processing.

Sentiment and Subjectivity Analysis
Annotating Tone, Polarity, and Opinion Intensity
This involves marking the emotional valence of a text (positive, negative, neutral), as well as its degree of enthusiasm or subjectivity. It can include nuances like anger, joy, surprise, or an intensity score.
This can also relate to the person’s tone and whether what is being said can be legally punishable.
→ To learn more, see the use case with video content moderation.

Part-of-Speech Tagging and Named Entity Recognition (POS Tagging & NER)
Identifying Grammatical Categories and Specific Entities
- POS Tagging: Categorizing each word based on its grammatical function (noun, verb, adjective, adverb, etc.).
- NER: Detecting and classifying named entities (people, organizations, locations, dates, etc.).
EXAMPLE :
Sentence: Marie sent an email to Paul yesterday.
POS : Marie (Proper Noun), sent (Verb), an (Determiner), email (Noun), to (Preposition), Paul (Proper Noun), yesterday (Adverb).
NER : Marie (Person), Paul (Person).

Semantic and Syntactic Segmentation and Annotation
Breaking Down and Structuring Language
This involves segmenting text into sentences, paragraphs, or other relevant linguistic units, followed by analyzing the syntactic structure (constituency or dependency parsing), lexical disambiguation, and annotating semantic roles.
EXAMPLE
Constituency Parsing:
The woman saw the man with a telescope.
→ [The woman [saw [the man] [with [a telescope]]]]
or
→ [The woman [saw [the man [with [a telescope]]]]]
Dependency Parsing :
The black cat sleeps on the sofa.
sleeps→ rootcat→subject of sleepsblack→ adjective ofcaton→ prepositional complement ofsleepssofa→ object ofon

Relationship Annotation
Identifying Links Between Expressions or Events
This involves identifying expressions that refer to the same entity in a text (coreference), as well as other semantic links (cause-effect, condition, opposition, inclusion, etc.).
EXAMPLES
- Cause-Effect Relationship
The rain caused floods.
Relationship: cause (rain) → effect (floods).
- Conditional Relationship
If the traffic is light, we’ll arrive on time.
Relationship: condition (light traffic) → result (arrive on time).
- Opposition Relationship
He loves the sea, but she prefers the mountains.
Relationship: opposition (sea ↔ mountains).
- Inclusion/Belonging Relationship
Paris is the capital of France.
Relationship: capital of France → Paris.

Annotation for Large Language Model Training
Data Preparation for Fine-Tuning and Alignment
RLHF (Reinforcement Learning from Human Feedback): Qualitative or comparative annotation of model-generated responses to optimize its behavior.
Supervised Fine-Tuning (SFT): Creation of prompt/response pairs or supervised datasets to train a model.
EXAMPLES
- Preference Annotation for RLHF
- Goal : Improve model behavior by rating or ranking its responses.
- Prompt: Explain gravity to a 6-year-old child.
Response A : Gravity is an invisible force that makes things fall towards the Earth. ✅ (clearer and more suitable)
Response B : Gravity is the acceleration of a body proportional to mass and inversely proportional to the square of the distance. ❌ (too technical)
→ Annotation : Mark A as preferable to B.
- Providing Correct Prompt/Response Pairs for SFT Model Training
Prompt : Give me three synonyms for the word “happy.”
Expected Response : joyful, content, satisfied
Quality annotations with a fair commitment
Full-Time Annotators
After the trial period, we only hire annotators on permanent contracts (CDI). We have professionalized the annotator role by selecting rigorous and patient individuals.
Experts at Your Fingertips
We have an experienced project management team, made up of former data scientists, capable of successfully leading the most complex projects.
CSR (Corporate Social Responsibility) and Social Policy
We work in close collaboration with Le Relais Madagascar, a company that aims to socially reintegrate individuals who have faced difficult life circumstances. 20% of our staff have overcome significant life challenges.
They trust us




