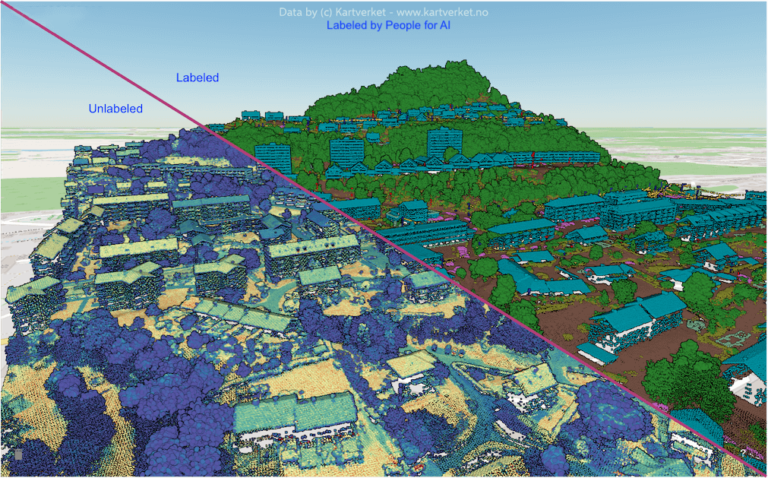
Introduction
In the world of artificial intelligence, we often marvel at the complexity of algorithms and the power of models. We talk about neural networks, deep learning, and massive computations. Yet behind every innovation lies one simple but crucial element: data — and more specifically, annotated data.
It’s what feeds the models and determines their ability to learn correctly, generalize, and produce reliable results. Without a solid foundation, even the most sophisticated algorithms are destined to fail.
1. The Quantity Myth: “The More Data, the Better the Model”
For a long time, the prevailing idea was that quantity outweighed everything else. The more data a model was fed, the “smarter” it became. But that assumption is incomplete.
Recent studies show that data quality has a direct impact on model performance. Investing in quality is often more effective than simply increasing the number of examples.
Conversely, incomplete, biased, or poorly annotated data can lead to unreliable, unfair, or even dangerous models — especially in critical decision-making contexts. Data quality is no longer a mere technical detail; it’s a strategic priority for ensuring performance, fairness, and safety in AI systems.
Key references:
- The Effects of Data Quality on Machine Learning Performance (L. Budach et al., Nov 2022)
- Data Quality Aware Approaches for Addressing Model Drift of Semantic Segmentation Models (Samiha Mirza et al., 2024)
- Data Quality Matters: Quantifying Image Quality Impact on Machine Learning Performance (Christian Steinhauser et al., 2025)
2. The Importance of Data Quality for Model Accuracy
Before building a high-performing model, it’s essential to understand what “data quality” truly means. It’s not a single criterion but a multidimensional concept that spans the entire dataset lifecycle — from collection to final preparation.
Data quality can be viewed along three complementary axes:
a) Raw Data Quality
Raw data quality — whether images, text, or audio — forms the foundation of learning. It’s measured by clarity, integrity, and the absence of errors or artifacts:
- Images: sharp, properly framed, with good contrast and without distortion or missing pixels.
- Texts: coherent, properly structured, without illegible characters.
- Audios: clear, without background noise or interruptions, with consistent volume.
Poor raw data introduces missing or incorrect information, limiting the model’s ability to identify key features and generalize to real-world situations.
b) Annotation Quality
Annotation quality depends on several key criteria:
- Accuracy: Correct labeling and precise object or region localization
- Consistency: Uniform annotation practices across annotators
- Completeness: Full labeling of all relevant objects or information
Any gap in these criteria introduces confusion and directly impacts model reliability.
c) Dataset-Level Quality
Overall dataset quality depends on:
- Class balance — to prevent bias
- Diversity — to prepare the model for varied real-world scenarios
- Representativeness — to reflect the true distribution of the application domain
Combining these three dimensions produces a dataset that enables models to learn effectively, generalize properly, and deliver dependable results. Each level is interdependent: perfect raw data loses its value if poorly annotated, and precise annotations are useless if the dataset lacks balance and representativeness.
3. The Added Value of a Specialized Partner: People for AI
Quality annotation is a complex challenge that requires expertise and rigor. People for AI stands out with a human-centered, quality-driven approach, ensuring every project benefits from accurate and reliable datasets.
Unlike traditional crowdsourcing, our annotators are full-time long term employees — trained, dedicated, and specialized for each project. This approach guarantees consistent expertise and maximum data security, even for sensitive or technical use cases.
a) Iterative Methodology
Our iterative methodology lies at the heart of our process. Instead of a one-shot annotation cycle, we favor continuous feedback loops with the client, allowing precise alignment between model needs and annotation work.
The process unfolds in two key phases:
Proof of Concept (POC) Phase
This stage involves annotating a representative data sample to test and validate initial instructions. It includes:
- Verifying annotators’ understanding of the guidelines
- Identifying ambiguities or unanticipated edge cases
- Gathering immediate client feedback on categorization or desired detail level
- Refining the guidelines with clarifications and concrete examples
The goal is to ensure a shared understanding between annotators and client before full-scale production.
Production Phase
Once validated, the project moves to production. Annotators apply the guidelines across the dataset — but the process remains iterative and collaborative:
- Ongoing client feedback refines annotations based on evolving model needs
- Instructions are continuously updated to ensure precision and adaptability
- Constant monitoring detects and corrects deviations early, preserving dataset quality
This approach ensures production never becomes a mechanical task — it remains collaborative, flexible, and quality-focused throughout the project.
b) Quality Assurance Process
People for AI strengthens this methodology with a rigorous quality assurance framework:
- Annotator training: Practical test sessions with detailed feedback to harmonize practices; project entry validated by a project manager
- Automated checks and sample reviews: Immediate error detection and feedback loops
- Quality metrics tracking: Regular client reports measuring accuracy, consistency, and completeness
This combination of human expertise and structured processes delivers reliable datasets — even for the most complex AI projects.
Conclusion
Data quality isn’t optional — it’s the cornerstone of every successful AI project. Focusing solely on quantity leads to hidden costs and subpar performance.
With People for AI, you benefit from human expertise, a proven methodology, and precise, trustworthy datasets. Your models become more performant, robust, and sustainable.
Choosing People for AI means securing the very foundation of your AI projects — and turning your ambitions into tangible, measurable results.
Learn more about our data annotation techniques with our Complete guide to data annotation techniques.